Hadoop 运行环境搭建
一、Hadoop 组成
Hadoop 的组成
四、RDD弹性分布式数据集介绍
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
-
RDD : 弹性分布式数据集
-
累加器:分布式共享只写变量
-
广播变量:分布式共享只读变量
接下来我们一起看看这三大数据结构是如何在数据处理中使用的。
三、Spark运行架构
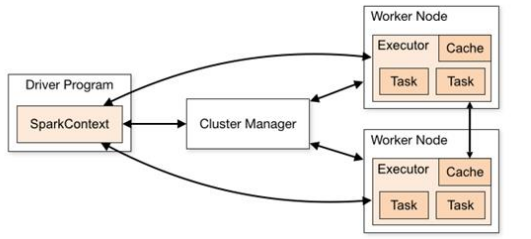
二、Spark运行环境
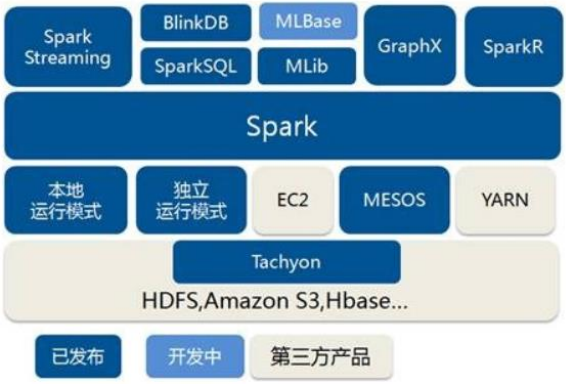
Spark 作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行, 在国内工作中主流的环境为Yarn,不过逐渐容器式环境也慢慢流行起来。接下来,我们就分别看看不同环境下 Spark 的运行。
Scala常见操作总结
Scala常见操作总结
Scala中==、eq与equals的区别
推荐先了解一下hashCode、identityHashCode、equals和==的原理,再来看Scala中==、eq与equals的区别
一、Spark快速入门
Spark快速入门
八、Scala编程之递归思想
Scala编程之递归思想
七、Scala之函数式编程(高级部分)
Scala之函数式编程(高级部分)