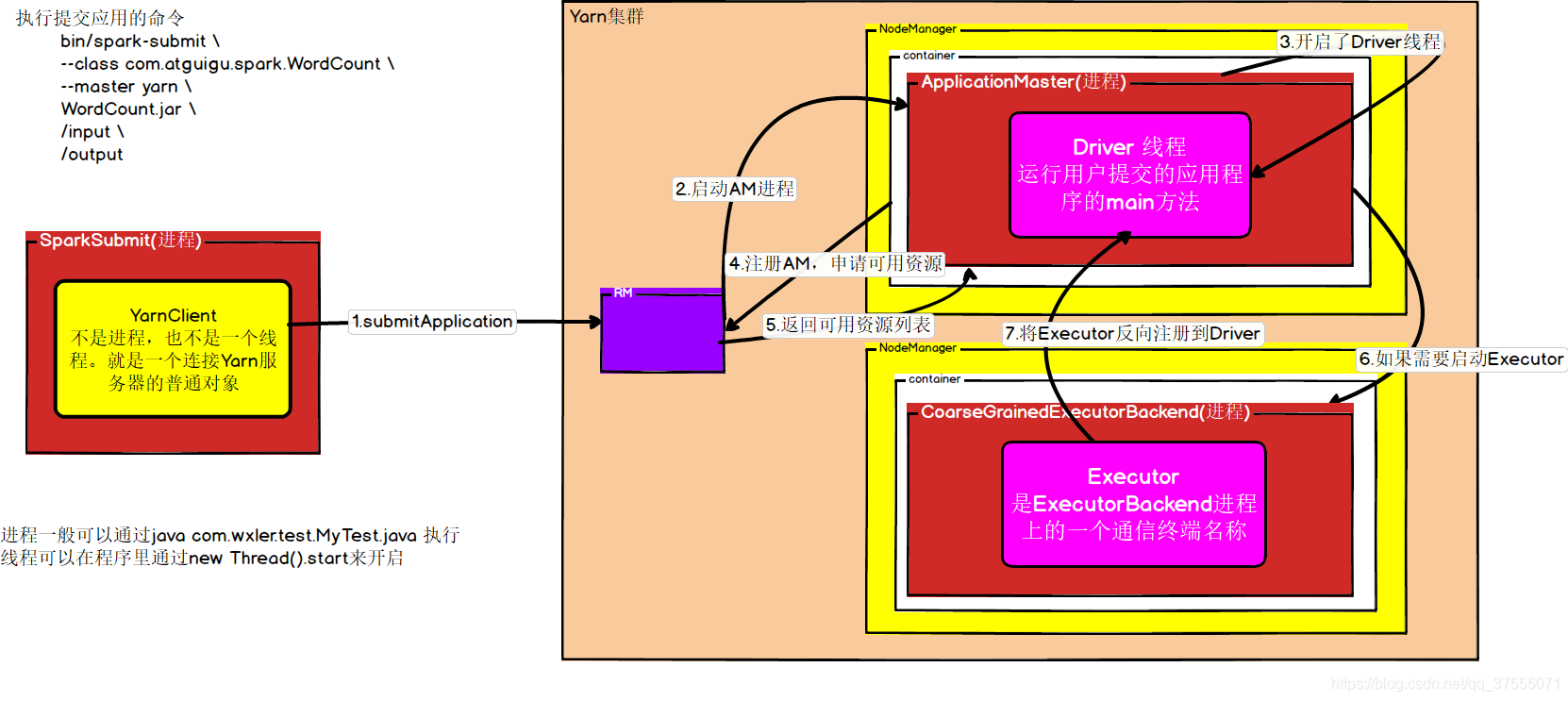
Yarn Cluster任务提交分为三个部分:
用户编写好的Spark应用程序提交到Yarn上(截止到ApplicationMaster启动Driver那一步)
Driver对用户的应用程序进行App->Job->Stage->Task划分
Driver分发Task到Executor上
首先,我将自己总结的详细流程介绍一下,
然后,从源码部分一步一步解释上面的具体实现。
先来一张图:
图上不全面,但可以作为参考。
(1)用户编写好的Spark应用程序提交到Yarn上
注意区别SparkSubmit里的main方法和用户提交的应用程序的main方法
用户执行spark下的spark-submit提交程序
SparkSubmit里的main 方法开启yarnClient进程
在yarnClient中,首先与向Yarn服务器发送请求,ResourceManager生成新的作业id后返回给yarnClient
在yarnClient中,将Application的上下文信息封装到containerContext,然后通过yarnClient.submitApplication提交到Yarn服务器
当ResourceManager收到yarnClien的submitApplciation() 的请求时, 就将该请求发给调度器(scheduler), 调度器分配 container, 然后ResourceManager在该container内启动ApplicationMaster进程
这里注意Cluster模式下,container启动的是ExecutorLauncher进程,但不管是什么方式,它实际上都是运行的ApplicationMaster进程,只不过client模式下是从ExecutorLauncher的main方法启动ApplicationMaster,而cluster执行是启动直接ApplicationMaster进程,并且cluster模式还会在ApplicationMaster启动driver线程
在ApplicationMaster进程中,会开启一个名为Driver的线程(等Executor注册后才会执行)。此外,ApplicationMaster还会作为client向ResourceManager进行注册以申请资源(即申请Executor),在申请资源时,ApplicationMaster首先获取已分配的资源详情(这里有机架感知和最近距离原则),然后比较应用需要的executor个数和正在运行的executor个数,如果应用需要的executor个数大于正在运行的executor个数,则通过ResourceManager在合适的Container上启动对应数量的CoarseGrainedExecutorBackend进程,以满足程序运行的需要。
在CoarseGrainedExecutorBackend进程中,会通过setupEndpoint方法命名一个Executor通信终端,通过这个通信终端与Driver进行交互。它首先执行onStart方法反向注册到Driver上,然后Driver就知道有哪些Executor提供服务了。
当所有的Executor全部注册完成后,Driver线程开始执行用户提交的应用程序的main方法
(2)Driver对用户的应用程序进行App->Job->Stage->Task划分 (主要是在DAGScheduler类中执行的)
Driver线程执行用户提交的应用程序的main方法,它会把当前提交的作业封装成JobSubmitted对应放到eventQueue里,然后,会开启线程从eventQueue获取JobSubmitted,然后调用onReceive方法进行处理。
在onReceive的doOnReceive中执行dagScheduler.handleJobSubmitted去处理提交的作业。
在handleJobSubmitted里面会对job进行阶段划分,具体如下:
划分Task的做法是这样的:首先获取最前面的阶段 (没有父阶段的阶段),根据当前阶段的类型来创建任务,如果是ShuffleMapStage,则创建ShuffleMapTask,如果是ResultStage,则创建ResultTask。partitionsToCompute),
创建完任务后放进集合里面去,然后做判断,如果任务数大于0,说明有Task需要处理,则会调用submitTask进行处理
submitTasks中传入的参数是TaskSet,因此会先将所有的Task封装成TaskSet,然后在执行submitTasks 提交任务,TaskSet包含的信息如下:
有哪些Task
这些Task所属于的阶段
Task的优先级
submitTasks 方法是如何执行的呢?即Driver如何分发Task到Executor上的,具体看下面:
(3)Driver分发Task到Executor上 (主要是在TaskSchedulerImpl 类中执行的)
submitTasks是抽象方法,具体实现是在TaskSchedulerImpl
在TaskScheduler,创建了TaskSetManager对TaskSet进行封装,为了方便做资源调度。
底层SchedulerBackend与ExecutorBackend通信,将任务发送给Executor后,SchedulerBackend也会接收Executor端返回的消息,从而实时监测任务的运行状态,SchedulerBackend将任务的运行状态报告给TaskSetManager,如果任务运行失败了,由TaskSetManager决定将任务发送给其它的Executor。
将封装好的TaskSetManager放到资源调度器中,driver上的任务调度器有两种类型:
先进先出:FIFOSchedulableBuilder(默认根据FIFO进行任务调度)
公平:FairSchedulableBuilder
注意:这是Spark本身调度机制,即driver上任务调度器,Yarn的资源调度在启动ApplicationMaster和ExecutorBackend的时候就已经调度完了
然后,调用SchedulerBackend的receiveOffers方法给driverEndpoint发送ReviveOffer消息
在driver端底层通信类的实现是CoarseGrainedSchedulerBackend,SchedulerBackend负责提供可用资源,SchedulerBackend有多种实现,分别对接不同的资源管理系统
driverEndpoint收到ReviveOffer消息后调用makeOffers方法,过滤出活跃状态的Executor,将Task进行序列化,发送给Executor
driverEndpoint也是在SchedulerBackend中
ExecutorBackend接收Task(在Executor端底层通信的类是CoarseGrainedExecutorBackend),进行反序列化,从线程池中获取线程,根据任务任务类型的不同,从而执行不同的任务,任务分为ShuffleMapTask和ResultTask
需要注意的是,跟踪源码的时候添加一下依赖:
1 2 3 4 5 <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-yarn_2.11</artifactId > <version > 2.1.1</version > </dependency >
下面为了便于分析,这里只列出关键步骤。tab符号代表进入到方法里面,用-、*、>、~代表不同的方法层级。
(1)用户编写好应用程序执行提交命令:
1 2 3 4 5 6 7 bin/spark-submit \ --class com.wxler.spark.WordCount \ --master yarn \ --deploy-mode cluster \ WordCount.jar \ /input \ /output
(2)底层运行 bin/java org.apache.spark.deploy.SparkSubmit "$@"
"$@"是把所有的参数拿过来
(3)运行SparkSubmit(全类名为org/apache/spark/deploy/SparkSubmit.scala)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 -main方法 //对参数进行封装 *val appArgs = new SparkSubmitArguments(args) //提交 *submit(appArgs) //准备提交环境 //childMainClass有两种取值 //cluster模式:childMainClass = "org.apache.spark.deploy.yarn.Client" //client模式: childMainClass = "com.wxler.spark.WordCount" >val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args) >doRunMain() &runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose) //根据字符串类型的全类名获取类对象 ~ Class.forName(childMainClass) //根据类对象获取当前类的main方法 ~val mainMethod = mainClass.getMethod("main") //调用指定类的主方法 ~mainMethod.invoke(null, childArgs.toArray) //下面进入org.apache.spark.deploy.yarn.Client执行main方法
(4)运行Client(全类名为org.apache.spark.deploy.yarn.Client)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 -main方法 //对参数进行封装 *val args = new ClientArguments(argStrings) //运行run方法 *new Client(args, sparkConf).run() //此时会yarnClient = YarnClient.createYarnClient //发送请求给Yarn服务器,获取AppId >this.appId = submitApplication() //yarnClient向Yarn服务发送请求,ResourceManager分配新的作业id &val newApp = yarnClient.createApplication() &val newAppResponse = newApp.getNewApplicationResponse() &appId = newAppResponse.getApplicationId() //创建containerContext对象,containerContext里面封装了运行Application的上下文环境 //这里注意在不同的模式下启动进行不同 //cluster模式:org.apache.spark.deploy.yarn.ApplicationMaster //client模式:org.apache.spark.deploy.yarn.ExecutorLauncher &val containerContext = createContainerLaunchContext(newAppResponse) &val appContext = createApplicationSubmissionContext(newApp, containerContext) //提交用户应用程序到Yarn yarnClient.submitApplication(appContext) //里面会和ResourceManager通讯,申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster进程,在ApplicationMaster启动Driver线程,具体看org.apache.spark.deploy.yarn.ApplicationMaster
(5)运行ApplicationMaster(全类名为org.apache.spark.deploy.yarn.ApplicationMaster)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 -main方法 //对参数参数进行封装 *val amArgs = new ApplicationMasterArguments(args) // master里维护了AMRMClient *master = new ApplicationMaster(amArgs, new YarnRMClient) *master.run() >runDriver(securityMgr) &userClassThread = startUserApplication() //userClass即WordCount ~mainMethod = userClassLoader.loadClass(args.userClass).getMethod("main") //开启driver线程 ~userThread = new Thread #mainMethod.invoke ®isterAM() //client(AM)注册到RM上,申请可用资源 ~allocator=client.register //分配资源 ~allocator.allocateResources() //获取需要多少资源 +val allocatedContainers = allocateResponse.getAllocatedContainers() //分配资源(也有最近距离原则和机架感知) + handleAllocatedContainers(allocatedContainers) @runAllocatedContainers(containersToUse) //判断是否需要启动Executor >if (numExecutorsRunning < targetNumExecutors) >ExecutorRunnable.run >startContainer() >prepareCommand() >bin/java org.apache.spark.executor.CoarseGrainedExecutorBackend (粗粒度的Executor) //注意这里的join,阻塞主线程 &userClassThread.join()
targetNumExecutors是应用需要的executor个数,numExecutorsRunning是正在运行的executor个数。targetNumExecutors的个数可以由--num-executors(默认为2)指定。
(6)运行CoarseGrainedExecutorBackend(全类名org.apache.spark.executor.CoarseGrainedExecutorBackend)
1 2 3 4 5 6 7 8 -main方法 *run //Executor是ExecutorBackend进程上的一个通信终端名称 env.rpcEnv.setupEndpoint("Executor", new CoarseGrainedExecutorBackend) //在endpoint里面,通过执行onStart方法反向注册到Driver上,然后Driver就知道有哪些Executor提供服务了 onStart logInfo("Connecting to driver: " + driverUrl) rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap{...}
再补充一点,driver收到executor的消息后会给excutor回复(具体在CoarseGrainedSchedulerBackend类里)
Executor收到Driver的回复,这就表示注册成功了,然后创建Executor对象,等drive将任务发过来后来执行task(具体在CoarseGrainedExecutorBackend)。
到这里,我们已经把所有需要的Executor都启动完了,并且开启了driver线程来运行用户程序,下面是Driver对用户的应用程序进行App->Job->Stage->Task划分
这里就不一一贴上代码了
一旦遇到一个行动算子,就会提交一个job,即执行runJob操作,它会把当前提交的作业封装成JobSubmitted对应放到eventQueue里,然后,会开启线程从eventQueue获取JobSubmitted进行处理,然后调用onReceive方法进行处理。
onReceive的doOnReceive中执行dagScheduler.handleJobSubmitted去处理提交的作业。
在handleJobSubmitted里面会对job进行阶段划分,具体如下:
创建一个ResultStage,同时根据宽依赖来创建ShuffleMapStage,具体做法是:获取RDD最近的一个宽依赖(从后往前搜索的),再根据宽依赖创建ShufferMapStage,如果除了最近上级之外,还有祖先的宽依赖,那么把祖先宽依赖ShufferMapStage也创建了。现在所有的阶段都创建完了,然后划分Task。
首先获取最前面的阶段(没有父阶段的阶段),根据当前阶段的类型来创建任务,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 //在DAGScheduler类下: stage match { case stage: ShuffleMapStage => partitionsToCompute.map { id => val locs = taskIdToLocations(id) val part = stage.rdd.partitions(id) new ShuffleMapTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, stage.latestInfo.taskMetrics, properties, Option(jobId), Option(sc.applicationId), sc.applicationAttemptId) } case stage: ResultStage => partitionsToCompute.map { id => val p: Int = stage.partitions(id) val part = stage.rdd.partitions(p) val locs = taskIdToLocations(id) new ResultTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics, Option(jobId), Option(sc.applicationId), sc.applicationAttemptId) } }
如果是ShuffleMapStage,则创建ShuffleMapTask,如果是ResultStage,则创建ResultTask。
创建Task的时候,并不是一个阶段创建一个Task,而是根据当前阶段最后一个RDD的分区数遍历,根据分区来创建Task的,每一个分区创建一个Task(看上面的partitionsToCompute),
创建完任务后放进集合里面去,然后做判断,如果任务数大于0,说明有Task需要处理,则会调用submitTask进行处理(如下):
1 2 3 4 5 6 7 8 9 //在DAGScheduler.scala类下: if (tasks.size > 0) { logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")") stage.pendingPartitions ++= tasks.map(_.partitionId) logDebug("New pending partitions: " + stage.pendingPartitions) taskScheduler.submitTasks(new TaskSet( tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties)) stage.latestInfo.submissionTime = Some(clock.getTimeMillis()) }
submitTasks中传入的参数是TaskSet,因此会先将所有的Task封装成TaskSet,然后在执行submitTasks 提交任务,TaskSet包含的信息如下:
1 2 3 4 5 6 7 8 9 10 private[spark] class TaskSet( val tasks: Array[Task[_]], //有哪些Task val stageId: Int, //这些Task的阶段 val stageAttemptId: Int, val priority: Int, //Task的优先级 val properties: Properties) { val id: String = stageId + "." + stageAttemptId override def toString: String = "TaskSet " + id }
上面这些操作都是在Driver端进行的,具体如何将任务分发到Executor执行呢?看下面Driver分发Task到Executor上 ,其实就是看submitTasks 里面的执行细节
(1)Driver提交Task到Executor(在org.apache.spark.scheduler.DAGScheduler类里面)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 -执行submitMissingTasks方法 //每一个Task对应处理一个分区的数据,将多个Task放到TaskSet中进行提交 //该方法是抽象方法,具体实现在org.apache.spark.scheduler.TaskSchedulerImpl *taskScheduler.submitTasks(new TaskSet) //在Task之前,创建了TaskSetManager对TaskSet进行封装,为了方便做资源调度 >val manager = createTaskSetManager(taskSet, maxTaskFailures) //将封装好的TaskSetManager放到资源调度器中【这是Spark本身调度机制,即driver上任务调度器,Yarn的资源调度在启动ApplicationMaster和Executor的时候就已经调度完了】 //manager.taskSet.properties有两种 //先进先出: org.apache.spark.scheduler.FIFOSchedulableBuilder(默认根据FIFO进行任务调度) //公平:org.apache.spark.scheduler.FairSchedulableBuilder >schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties) //触发底层资源调度,该方法是抽象方法,在driver端底层通信的类是CoarseGrainedSchedulerBackend >backend.reviveOffers() //给Driver终端发送一条标记位ReviveOffers的消息,【一般是Task提交的时候,或者是资源变化的时候,会发送给driver重新做一些调度】 &driverEndpoint.send(ReviveOffers) &Driver终端会通过receive的方法,接收消息并对其进行处理 #case ReviveOffers =>makeOffers() //(下面两行)获取可用的Executor ~val activeExecutors = executorDataMap.filterKeys(executorIsAlive) ~val workOffers = activeExecutors.map //scheduler.resourceOffers(workOffers) 决定Task应该交给哪个Executor处理【具体分配到哪个Executor我们不用关心,现在关心的是怎么提交到Executor上去大的】 ~运行Task launchTasks(scheduler.resourceOffers(workOffers)) //因为要将Task提交到Executor运行,所以需要进行序列化 +val serializedTask = ser.serialize(task) //给Executor终端发送Task +executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
(2)Executor端接收Task并运行(在Executor端底层通信的类是CoarseGrainedExecutorBackend)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 -receive //对接收到的消息类型进行匹配,匹配LaunchTask *case LaunchTask(data) //对接收到的Task进行反序列化 >val taskDesc = ser.deserialize[TaskDescription](data.value) //运行Task >executor.launchTask //从线程池中获取线程,执行task &threadPool.execute(tr) #TaskRunner.run ~task.run +runTask(context) //根据任务类型的不同,从而执行不同的任务 ++ShuffleMapTask ++ResultTask
思考 :为什么要分不同的Task呢?