使用yolov5训练自动驾驶目标检测数据集BDD100K
使用yolov5训练自动驾驶目标检测数据集BDD100K!
一、什么是BDD100K
BDD100K是伯克利发布的开放式驾驶视频数据集,其中包含10万个视频和10个任务(因为把交通灯的颜色也区分了出来,实际上是13类分类任务),目的是方便评估自动驾驶图像识别算法的的进展。该数据集具有地理,环境和天气多样性,从而能让模型能够识别多种场景,具备更多的泛化能力。
由于硬件限制,我只里训练其中的图片数据,数据集按Train、Valid、Test三个部分,比例可以按照7:2:1分配,共近10张图片。
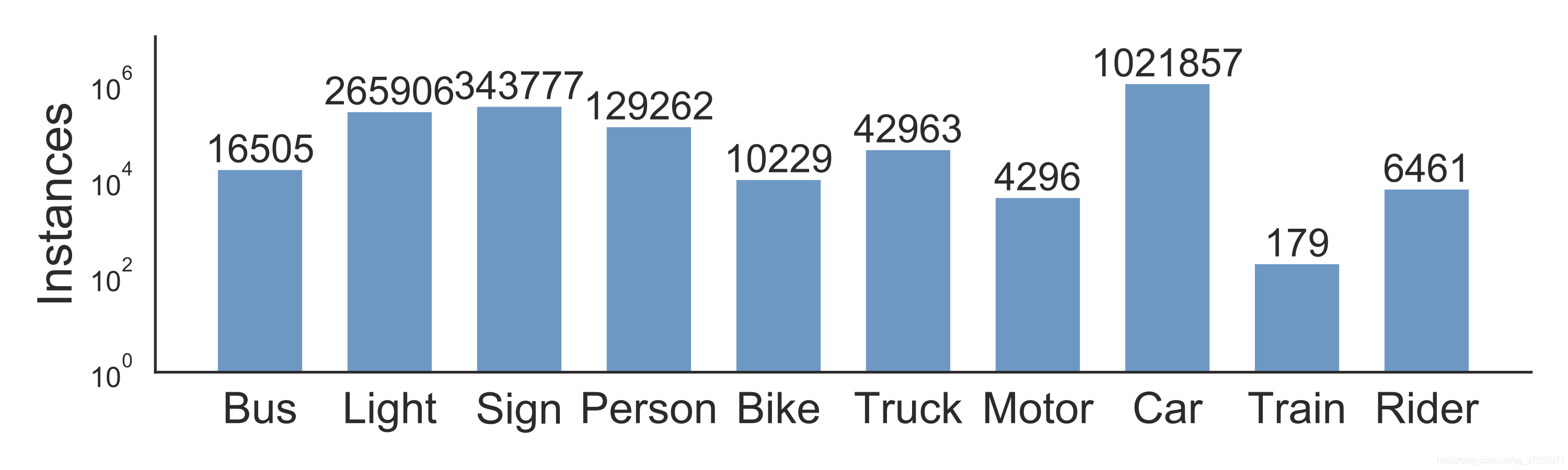
二、数据预处理
Bdd100k的标签是由Scalabel生成的JSON格式,虽然伯克利提供Bdd100k数据集的标签查看及标签格式转化工具。由于没有直接从bdd100k转换成YOLO的工具,因此我们首先得使用将bdd100k的标签转换为coco格式,然后再将coco格式转换为yolo格式。
YOLO家族独特的标签数据集格式为:每个图片文件.jpg,都有同一命名的标签文件.txt。标签文件中每个对象独占一行,格式为
1 | <object-class> <x> <y> <width> <height>。 |
其中:
<object-class>表示对象的类别序号:从0 到 (classes-1)。<x> <y> <width> <height>参照图片宽度和高度的相对比例(浮点数值),从0.0到1.0。
注意:
如下图所示:

(1)bdd 转化为coco格式
我的目的是识别包括不同颜色交通灯在内的所有交通对象,因此我们需要对原版的bdd2coco.py进行一些修改,以获取交通灯颜色并产生新的类别。这是修改完的核心代码:
1 | for label in i['labels']: |
在完成bdd100k格式到yolo格式的转换后,会获得两个文件:
- bdd100k_labels_images_det_coco_train.json
- bdd100k_labels_images_det_coco_val.json
(2)Coco 转化 yolo格式
在完成先前的转换之后,我们需要将训练集和验证集的coco格式标签转换为yolo格式。注意需要分别指定训练集和验证集图片位置,对应的coco标签文件位置,及生成yolo标签的目标位置:
1 | config_train ={ |
除此之外,我们还得将所有的类别写入bdd100k.names文件:
1 | person |
运行Bdd_preprocessing中的完整代码可以完成Bdd100k格式标签到YOLO标签格式的转换。
三、环境配置
Yolov5 需要的Pytorch版本>=1.5, Python版本3.7, CUDA版本10.2,可以把所需要的库放入requirement.txt文件,通过在shell中运行pip install -r requirement.txt 命令,可以自动安装所有依赖项。
1 | Cython |
Yolov5的默认YAML文件coco.yaml 中是coco数据集所有的类对象名称和类数量(80)。由于我是基于bdd100k数据集来训练检测少量特定交通物体的模型,不需要训练检测80类网络的模型,所以得重新创建一个uc_data.yaml文件来描述bdd100k数据集的数据特性。由于模型的输出不是coco数据集的80个类,而是13类,因此修改此处的输出类别数量为13。
1 | train: bdd100k/images/train |
四、修改模型结构
Yolov5通过models文件家中的cfg文件*.yaml来调整训练模型的结构。这里需要修改模型的对象预测层输出类别数量为13,也可以直接修改YAML文件下各个组件的细节(如数字),来重新定义自己的模型架构。
1 | # YOLO V5s |
五、迁移学习
迁移学习(Transfer learning) 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。下图为针对不同场景的迁移学习:

- 如果训练集小,训练数据与预训练数据相似,那么我们可以冻住卷积层,直接训练全连接层。
- 如果训练集小,训练数据与预训练数据不相似,那么必须从头训练卷积层及全连接层。
- 如果训练集大,训练数据与预训练数据相似,那么我们可以使用预训练的权重参数初始化网络,然后从头开始训练。
- 如果训练集大,训练数据与预训练数据不相似,那么我们可以使用预训练的权重参数初始化网络,然后从头开始训练或者完全不使用预训练权重,重新开始从头训练。
- 值得注意的是,对于大数据集,不推荐冻住卷积层,直接训练全连接层的方式,这可能会对性能造成很大影响。
现在的情况,符合上述第三种,通常只需要使用预训练的权重初始化网络,然后直接从头开始训练,从而更快的使模型有效收敛。但是由于之前没有人公开过对于Bdd100k数据集使用Yolov5预训练权重和不使用其训练权重的对比,并且 COCO数据集80类,而Bdd100k数据集13类,两者大部分类是不相似的。于是我分别使用YOLO V5s预训练权重和不使用其训练权重来训练基于Bdd100k数据集的对象识别网络,并对比它们的效果。
由于Bdd100k的数据集比较大,训练时间较长,因此只使用Yolov5s来训练基于Bdd100k自动驾驶数据集的对象检测深度网络。
六、训练BDD100K
现在,就可以训练了,下面是训练的一些重要参数:
1 | #训练参数(基于bdd100k数据集): |
七、评估性能
我将从如目标检测最常见几种指标Precision、Recal、F1 score、mAP评估模型的性能

其中,TP、TN、FP、FN表示如下:
True positives (TP): 正样本被正确识别为正样本,
True negatives(TN): 负样本被正确识别为负样本
False positives(FP): 假的正样本,即负样本被错误识别为正样本
False negatives(FN): 假的负样本,即正样本被错误识别为负样本
Precision、Recal、F1 score、mAP、maP@0.5含义如下:
- Precision其实就是在识别出来的图片中,True positives所占的比率。
- Recall 是测试集中所有正样本样例中,被正确识别为正样本的比例。
Accuracy体现识别正确T的结果与全体数据样本的比例 - F1是P-R的调和平均
- AP就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
- mAP是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均,得到的就是mAP的值。
- mAP@0.5:IoU阈值为0.5时的mAP
- mAP@0.5:0.95:表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
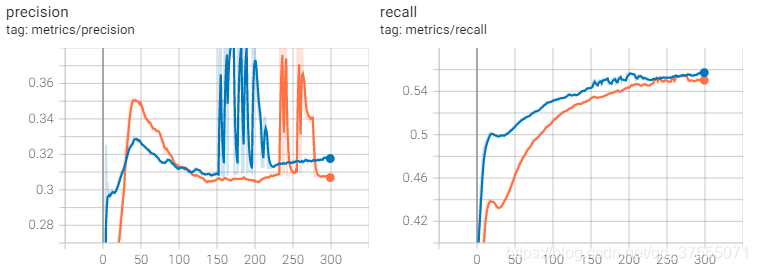
下面是训练结果:

在YOLOv5中,Loss分为三个部分:
- 一个是边框偏移量带来的误差,也就是giou带来的loss
- 一个是置信度带来的误差,也就是obj带来的loss
- 最后一个是类别带来的误差,也就是class(cls)带来的loss
这几部分Loss结果如下:

val loss:

从上面的结果中,可以看出(蓝色是迁移学习,橙色没采用迁移学习):
- 从图中可以看出,无论是采用迁移学习还是不采用迁移学习,模型都能很好的收敛。
- 迁移学习和从头开启训练的mAP@0.5最高达到均能达到46.5%,如果增加训练次数,mAP会更高。
- 从训练过程来看,迁移学习的收敛速度比不采用迁移学习的方式更快。
- 从最终结果来看,迁移学习的方式与不采用迁移学习的方式相差并不大,F1和mAP两者最终结果都一样,只有迁移学习的precision和recall稍高。
- 在分类损失(cls loss)中,epoch为230左右时,不采用迁移学习的方式loss更低,因此才某个点上,不采用迁移学习其实是更好的,原因应该是coco数据集的预训练模型与BDD100K并不是很相似。
- 总的来说,迁移学习的方式比不采用预训练模型能一定程度上减少训练时间开销,对于和COCO数据集相近的数据集,可以采用预训练的方式,如果时间充裕,从头开始训练更为妥当。
八、结语
至此,我基本上了解了Yolov5的网络结构,并且基于Bdd100k数据集训练了属于自己的自动驾驶对象检测模型。我认为Yolov5是个非常棒的开源对象检测网络,可能多人考虑到Yolov5的创新性不足,对Yolov5而议论纷纷,我觉得不管它现阶段配不配的上V5的名称,但既然称之为Yolov5,定有很多非常不错的地方值得我们学习。不可否认,它真的是一个快速而且强大的目标检测器。
我把BDD100K数据集地址上传到网盘上了,地址如下:
链接:https://pan.baidu.com/s/158XBxqDXIIAWkbHbja4cVQ
提取码:738o
想要本文实现代码的同学,可联系博主本人!