四、RDD弹性分布式数据集介绍
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
-
RDD : 弹性分布式数据集
-
累加器:分布式共享只写变量
-
广播变量:分布式共享只读变量
接下来我们一起看看这三大数据结构是如何在数据处理中使用的。
文章目录
1. IO与RDD
Java IO分为字节流与字符流:
- 字节流:传输过程中,传输数据的最基本单位是字节(8bit)的流。字节byte
- 字符流:传输过程中,传输数据的最基本单位是字符(16bit)的流。字符 char
字节流包含两个抽象类 InputStream(输入流)和OutputStream(输出流)。
字符流包含两个抽象类 Reader(输入流)和Writer(输出流)。
下面我们一步步来说明JavaIO的封装流程。
(1)FileInputStream
1 | InputStream in = new FileInputStream("path") |
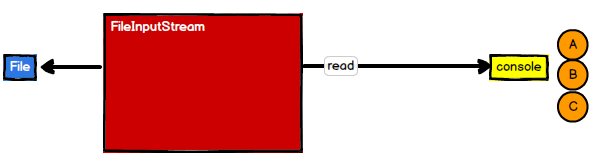
FileInputStream 每次读取一个字节都需要和磁盘进行交互。
(2)BufferedInputStream
1 | InputStream in = new BufferedInputStream(new FileInputStream("path")) |
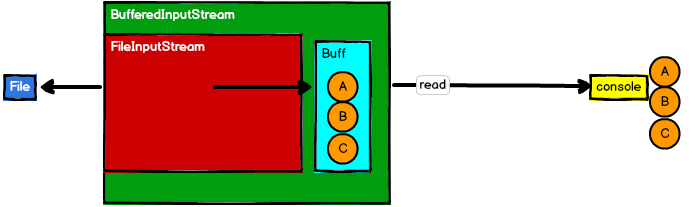
BufferedInputStream通过封装FileInputStream,把FileInputStream读取的一个个字节封装到Bufffer里,再从Buffer里获取数据
(3)BufferedReader
1 | Reader in = new BufferedReader( |
BufferedReader封装InputStreamReader,InputStreamReader封装了FileInputStream。首先,InputStreamReader将底层的字节流转成字符流,再放入其缓冲区,BufferedReader通过UTF-8编码格式,每遇到三个字节编码成一个中文,放入BufferedReader缓冲区中。
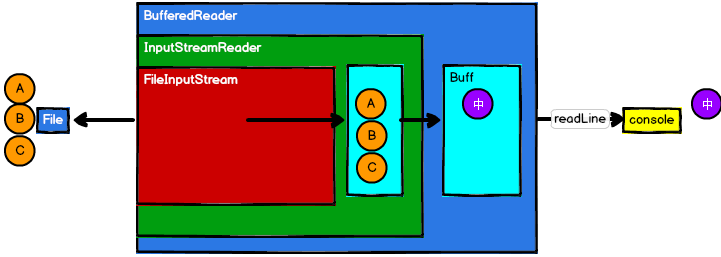
上面提到的一级一级封装,其实就是装饰者设计模式,执行的具体操作还是在最底层类。
(4)Scala的WordCount
1 | sc.textFile("input/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect |
执行过程如下图所示:
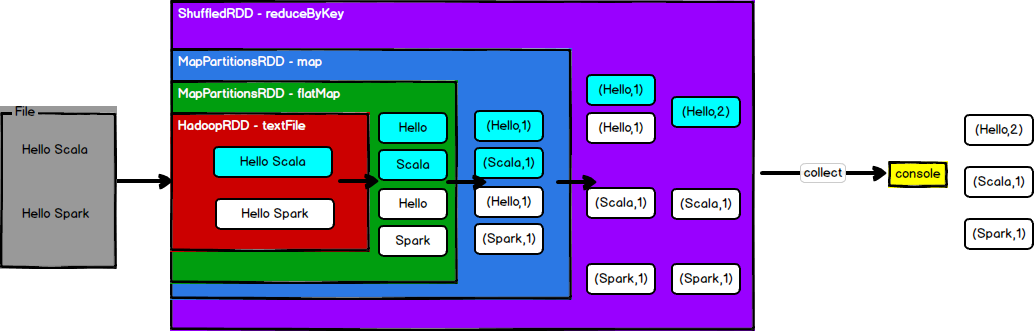
上面每个操作都继承了RDD这个抽象类,完成一个基本的功能。
- RDD的数据处理方式类似于IO流,也有装饰者设计模式。
- RDD的数据只有在调用collect方法时,才会真正执行业务逻辑操作。之前的封装全部都是功能(逻辑)的扩展,并没有真正执行
- RDD是不保存数据的,数据来了直接是往下走,但是IO可以临时保存一部分数据。
- rdd是最小的逻辑计算单元,一个rdd基本上只有一个功能,可以通过多个rdd组合的方式实现复杂的逻辑。
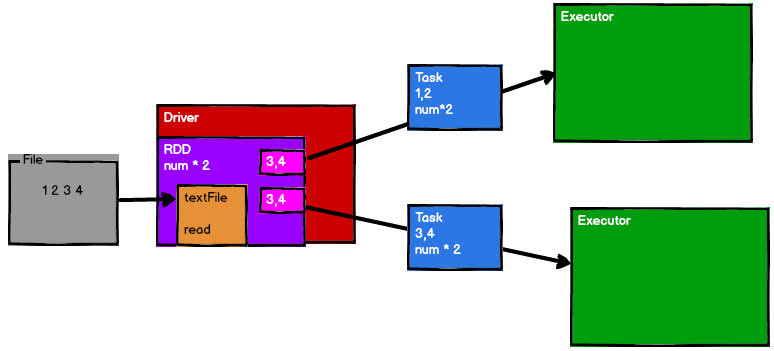
举一个小例子,比如我们想要(1,2,3,4)中的每个元素都乘以2,提交Spark实现,这时候Spark会封装成2个RDD(注意:RDD只封装了计算逻辑,不保存数据),以分片的方式将数据分成2个区,然后通过Drive将RDD封装的计算逻辑分发给不同的Executor,从而实现并行计算。
2. 什么是 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
- 弹性
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片(即分区)。
- 分布式:数据存储在大数据集群不同节点上
- 数据集:RDD 封装了计算逻辑,并不保存数据
- 数据抽象:RDD 是一个抽象类,需要子类具体实现
- 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
- 可分区、并行计算
3. RDD核心属性
查看RDD的源码,在其注释说明里面可以看到:
1 | Internally, each RDD is characterized by five main properties: |
(1)分区列表(A list of partitions)
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
1 | /** |
(2)分区计算函数(A function for computing each split)
Spark 在计算时,是使用分区函数对每一个分区进行计算。由于计算逻辑是事先封装好传递过来的,所以每个分区的计算逻辑完全相同
1 | /** |
(3)RDD 之间的依赖关系(A list of dependencies on other RDDs)
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系。
1 |
|
(4)分区器(可选)(a Partitioner for key-value RDDs)
当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区(可以理解为用于定义分区的规则)
1 |
|
Scala中的Option类是None和Some的父类,表示如果有值,则取Some,如果为空,则为None
(5)首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
1 | /** |
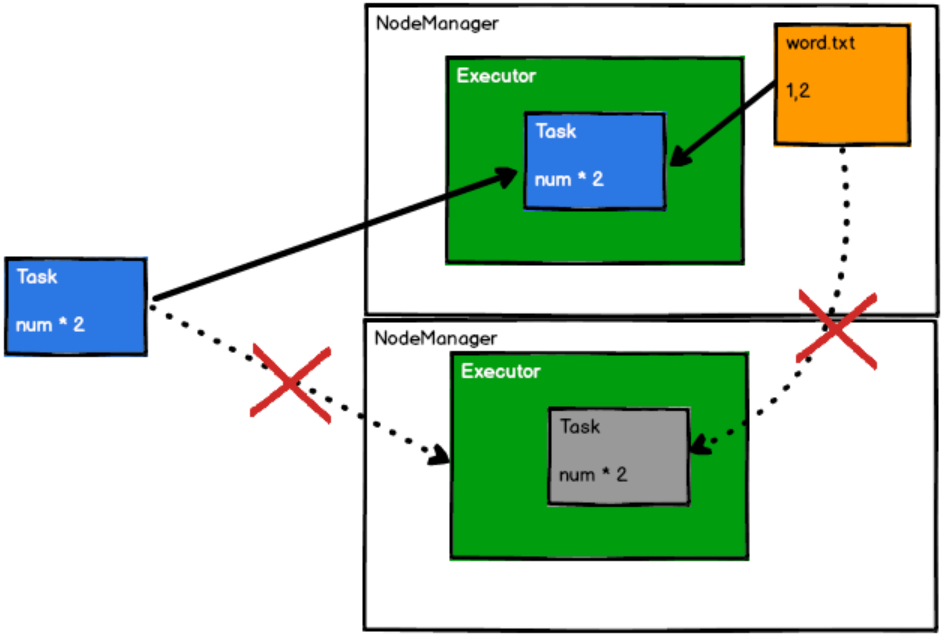
注意:由于数据是分布式存储的,如果需要的数据和某一个Executor在同一个节点上时,只需要将计算逻辑发给这个Executor就行,不需要移动数据。
首选位置:判断计算逻辑发送到哪个节点,效率最优,移动数据不如移动计算逻辑
如下图所示,如果需要的数据实现存在这个Executor所在的节点上,将计算逻辑分发给这个节点就行,不需要移动数据到其他地方。
4. 执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
RDD 是 Spark 框架中用于数据处理的核心模型,接下来我们看看,在 Yarn 环境中, RDD的工作原理:
- 启动 Yarn 集群环境
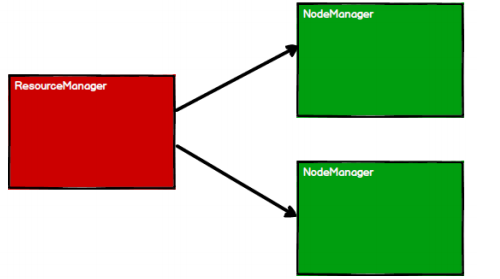
- Spark 通过申请资源创建调度节点和计算节点
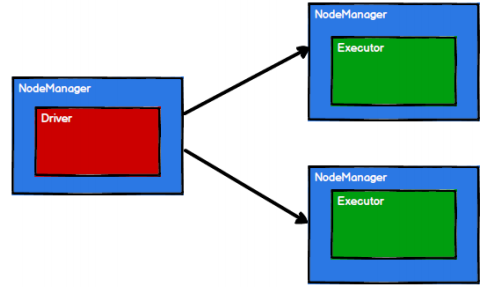
- Spark 框架根据需求将计算逻辑根据分区划分成不同的任务,并放到任务池当中
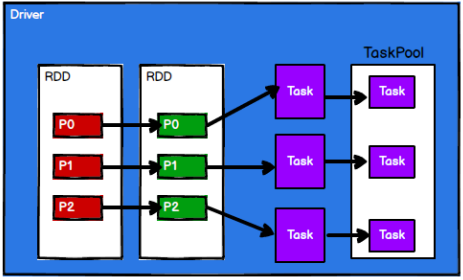
- 调度节点从任务池中将任务取出,根据计算节点状态发送到对应的计算节点进行计算
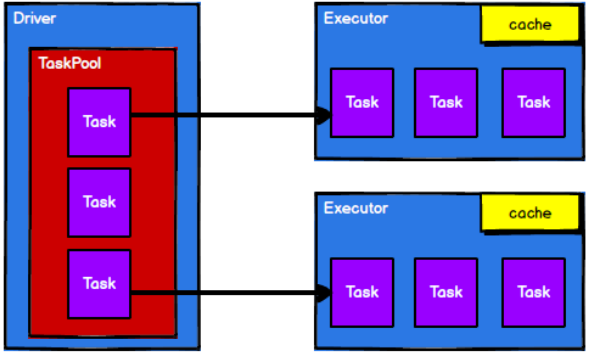
从以上流程可以看出 RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给Executor 节点执行计算,接下来我们就一起看看 Spark 框架中 RDD 是具体是如何进行数据处理的。
【资料推荐】
1、推荐一遍博客讲的特别棒
Spark中RDD的宽窄依赖 & 图解RDD执行中Application、Job、Stage、Task的关系
2、job和stage的概念区分