一、Spark快速入门
Spark快速入门
文章目录
1. Spark概述
1.1 Spark 是什么
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
1.2 Spark and Hadoop
Hadoop
Hadoop 是由 java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式
分析应用的开源框架
- 作为 Hadoop 分布式文件系统,HDFS 处于 Hadoop 生态圈的最下层,存储着所有的 数 据 ,支持着Hadoop 的 所 有 服 务 。 它 的 理 论 基 础 源 于 Google 的TheGoogleFileSystem 这篇论文,它是 GFS 的开源实现。
- MapReduce 是一种编程模型,Hadoop 根据 Google 的 MapReduce 论文将其实现,作为Hadoop 的分布式计算模型,是 Hadoop 的核心。基于这个框架,分布式并行程序的编写变得异常简单。综合了 HDFS 的分布式存储和 MapReduce 的分布式计算,Hadoop 在处理海量数据时,性能横向扩展变得非常容易。
- HBase 是对 Google 的 Bigtable 的开源实现,但又和 Bigtable 存在许多不同之处。HBase 是一个基于 HDFS 的分布式数据库,擅长实时地随机读/写超大规模数据集。它也是 Hadoop 非常重要的组件。
Spark
- Spark 是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎
- Spark Core 中提供了 Spark 最基础与最核心的功能
- Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
由上面的信息可以获知,Spark 出现的时间相对较晚,并且主要功能主要是用于数据计算,所以其实 Spark 一直被认为是 Hadoop 框架的升级版。
1.3 Spark and MR
Hadoop 的 MR 框架和 Spark 框架都是数据处理框架,那么我们在使用时如何选择呢?
Hadoop 的 MR 框架设计的初衷是一次性数据计算,所谓的一次性数据计算,就是框架在处理的时候,会从存储设备中读取数据,进行逻辑操作,然后将处理的结果重新存储到介质中。

而Spark框架把数据处理的中间结果放入内存中,为下一次的计算提供了便利

- Hadoop MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。所以 Spark 应运而生,Spark就是在传统的MapReduce计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的 RDD 计算模型。
- 机器学习中 ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。 MR这种模式不太合适,即使多 MR 串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR 显然不擅长。而Spark 所基于的 scala 语言恰恰擅长函数的处理。
- Spark 是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比 MapReduce 丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
- Spark 和 Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
- Spark Task 的启动时间快。Spark 采用 fork 线程的方式,而 Hadoop 采用创建新的进程的方式。
- Spark 只有在 shuffle 的时候将数据写入磁盘,而 Hadoop 中多个 MR 作业之间的数据交互都要依赖于磁盘交互。
- Spark 的缓存机制比 HDFS 的缓存机制高效。
经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark 确实会比 MapReduce更有优势。但是 Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败。此时, MapReduce 其实是一个更好的选择,所以 Spark并不能完全替代 MR。
1.4 Spark核心模块

- Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的 - Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。 - Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。 - Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。 - Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。
2. Spark快速上手
接下来,就让咱们走进 Spark 的世界,了解一下它是如何带领我们完成数据处理的。
2.1 增加 Scala 插件
Spark 由 Scala 语言开发的,所以本课件接下来的开发所使用的语言也为 Scala,咱们当前使用的 Spark 版本为 3.0.0,默认采用的 Scala 编译版本为 2.12,所以后续开发时。我们依然采用这个版本。开发前请保证 IDEA 开发工具中含有 Scala 开发插件

2.2 增加依赖关系
修改 Maven 项目中的 POM 文件,增加 Spark 框架的依赖关系。 这里基于 Spark3.0 版本,使用时请注意对应版本。
1 | <dependencies> |
2.3 WordCount
为了能直观地感受 Spark 框架的效果,接下来我们实现一个大数据学科中最常见的教学案例 WordCount
核心思想:缺什么补什么
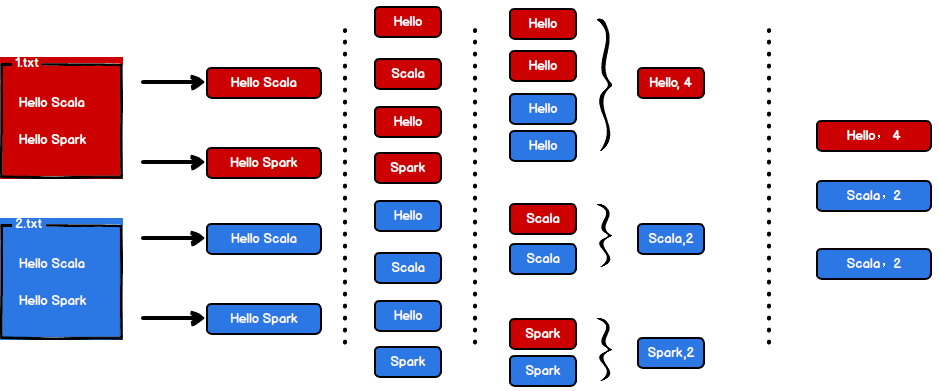
代码如下:
1 | package com.layne.spark.core.wc |
实现方式2
1 | package com.layne.spark.core.wc |
实现方式3
1 | package com.layne.spark.core.wc |
执行过程如下:
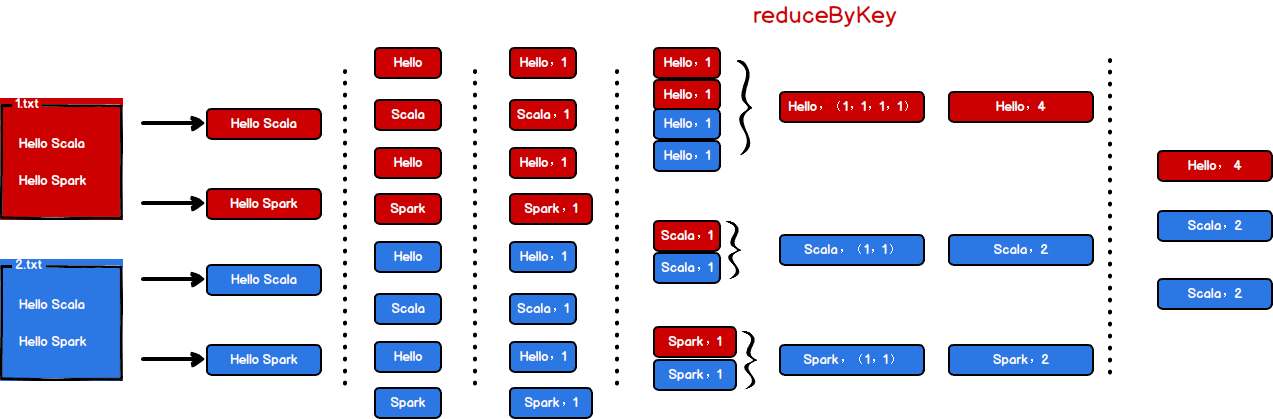
执行过程中,会产生大量的执行日志,如果为了能够更好的查看程序的执行结果,可以在项目的 resources 目录中创建 log4j.properties 文件,并添加日志配置信息:
1 | # ERROR级别,即只有错误的时候才会打印,平时就打印了 |
2.4 异常处理
如果本机操作系统是 Windows,在程序中使用了 Hadoop 相关的东西,比如写入文件到HDFS,则会遇到如下异常:

出现这个问题的原因,并不是程序的错误,而是 windows 系统用到了 hadoop 相关的服务,解决办法是通过配置关联到 windows 的系统依赖就可以了。

把这个路径添加到系统环境变量里面