hadoop完全分布式集群搭建
强烈建议先看一遍hadoop伪分布式集群搭建,然后再按本文的hadoop完全分布式集群搭建进行配置。
集群规划
四台服务器,分别为layne1~4,分布如下:
- layne1作为NameNode服务器
- layne2作为SecondaryNameNode和DataNode服务器
- layne3、layne4作为DataNode服务器
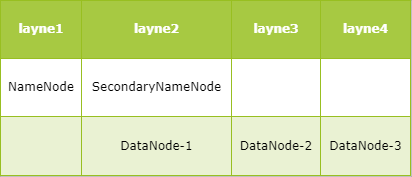
HDFS完全分布式搭建
详细步骤如下:
1、四台服务器之间互相均可以免密登录
可参考我之前的博客多台服务之间免密登陆
2、四台服务器JDK安装并配置环境变量
可参考rpm安装jdk
3、先在layne1上配置好,然后将配置好的hadoop拷贝到layne2~layne4上,这里所有配置都先在layne1上进行。
将hadoop安装包拷贝到layne1上并解压,然后进行如下配置:
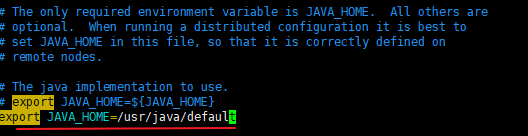
由于通过SSH远程启动进程的时候默认不会加载/etc/profile设置,JAVA_HOME变量就加载不到,需要手动指定。
在/opt/hadoop-2.6.5下,输入vim ./etc/hadoop/hadoop-env.sh,找到JAVA_HOME所在的行,并改为export JAVA_HOME=/usr/java/default。
1 | [root@layne1 hadoop-2.6.5]# pwd |
(2)修改slaves指定DataNode的位置
1 | /opt/hadoop-2.6.5/etc/hadoop |
(3)配置hdfs-site.xml
指定SecondaryNameNode的位置
1 | [root@layne1 hadoop]# pwd |
修改为如下内容:
1 | <configuration> |
(4)配置core-site.xml
这里是配置NameNode的位置和hadoop的存储目录
1 | [root@layne1 hadoop]# pwd |
修改为:
1 | <configuration> |
4、将第3步配置好的hadoop拷贝到layne2~node4上
先将layne1上的hadoop目录打成压缩包
1 | [root@layne1 opt]# pwd |
将/opt/hadoop-2.6.5.tar.gz 拷贝到layne2、layne3、layne4的对应目录中,即分别执行:
1 | scp hadoop-2.6.5.tar.gz layne2:/opt |
然后,在layne2、layne3、layne4分别解压
1 | tar -zxvf hadoop-2.6.5.tar.gz |
最后,删除四台虚拟机上的hadoop-2.6.5.tar.gz
1 | rm -f hadoop-2.6.5.tar.gz |
5、配置环境变量
在layne1上配置环境变量,在/etc/profile中最后一行加入:
1 | export JAVA_HOME=/usr/java/default |
然后,将etx/profile分别拷贝到layne2、layne3、layne4,再分别执行source /etc/profile使其立即生效。
6、格式化并启动
在layne1上执行:hdfs namenode -format
启动即可(该命令在四台服务器上哪一台执行都可以):start-dfs.sh
在四台机器上分别输入jps即可显示以下信息:
1 | layne1上显示 |
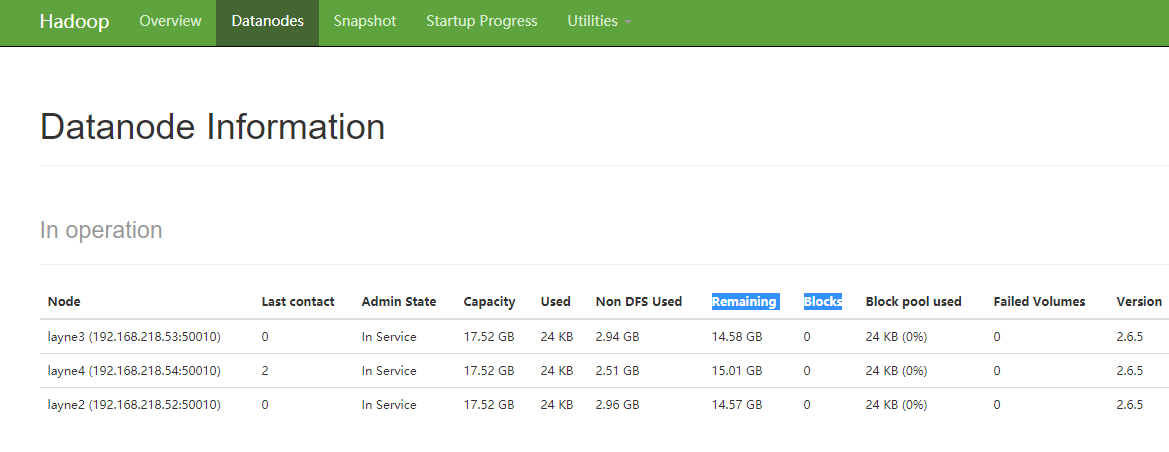
访问:http://layne1:50070,点击DataNodes一栏,会出现如下界面:
7、上传文件
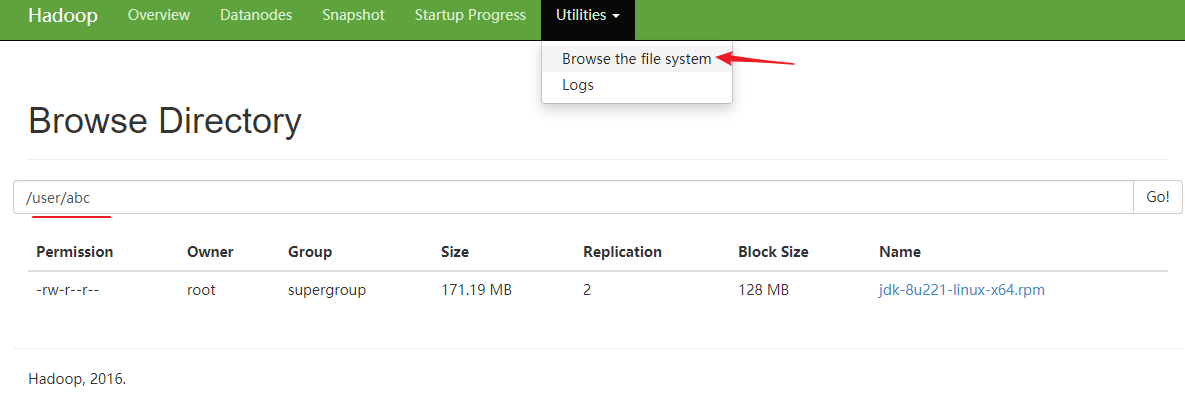
1 | [root@layne4 apps]# hdfs dfs -mkdir -p /user/abc |
上述命令将文件jdk-8u221-linux-x64.rpm上传到hadoop的/user/abc目录下,注意该目录不是Linux系统中的目录,这两者没关系。
在界面中可以看到上传的文件:
8、关闭hadoop集群
执行stop-dfs.sh关闭hadoop集群,该命令在hadoop集群中任意一台虚拟机执行均可。