hadoop伪分布式集群搭建
基础设施
基础设施环境如下:
- jdk 1.7+(提前设置好环境变量)
- ssh自己和自己之间进行免密登陆,如在layne1上执行
ssh layne1 - 时间同步
- 设置本机ip
- 设置主机名
可参考Linux切换运行级别、关闭防火墙、禁用selinux、关闭sshd、时间同步、修改时区、拍摄快照、克隆操作、修改语言环境。
这里不得不提Linux系统远程执行和远程登陆的区别:
- 远程执行:不需要用户交互,而是用户直接给出一个命令,直接在远程执行,不会加载
/etc/profile - 远程登陆:返回一个交互接口,返回接口
/bash会加载/etc/profile
操作步骤
我在主机名为layne1上搭建hadoop伪分布式集群,详细步骤如下
1、配置免密钥
1 | ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa |
id_dsa.pub存放每台服务器自己的公钥authorized_keys存放的也是服务器的公钥,不过除了自己的公钥外,也可以存放其它服务器的公钥。
再执行ssh layne1,让其自己和自己之间进行免密登陆。
2、上传hadoop的tar包hadoop-2.6.5.tar.gz到Linux系统的/opt/apps目录下
3、解压hadoop-2.6.5.tar.gz到/opt目录
1 | [root@layne1 apps]# tar -zxvf hadoop-2.6.5.tar.gz -C /opt |
4、删除hadoop-2.6.5/share/下的doc目录,doc里面是一些页面和文档,在Linux上没用,删除以后我们把这个hadoop复制到其他服务器上速度比较快
1 | [root@layne1 hadoop-2.6.5]# pwd |
5、添加hadoop环境变量
将HADOOP_HOME以及HADOOP_HOME/bin和HADOOP_HOME/sbin添加到环境变量,在/etc/profile里最后一行添加:
1 | export HADOOP_HOME=/opt/hadoop-2.6.5 |
再执行source /etc/profile使其立即生效。
6、hadoop-env.sh配置
由于通过SSH远程启动进程的时候默认不会加载/etc/profile设置,JAVA_HOME变量就加载不到,需要手动指定。
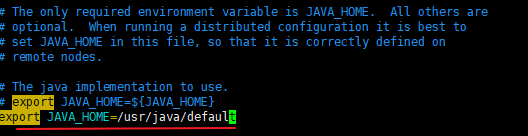
在/opt/hadoop-2.6.5下,输入vim ./etc/hadoop/hadoop-env.sh,找到JAVA_HOME所在的行,并改为export JAVA_HOME=/usr/java/default。
1 | [root@layne1 hadoop-2.6.5]# pwd |
7、配置core-site.xml
1 | [root@layne1 hadoop]# pwd |
这个文件指定的是namenode的访问
1 | <configuration> |
配置文件拷贝后格式不美观,可以通过以下方式格式化:
- 在vim命令按ESC回报命令模式,把光标定位在
<configuration>行首 - 输入
Ctrl+V - 按键盘上的下箭头按钮,直到
<configuration/> - 输入
:!xmllint -format -,然后回车 - 删除
<configuration>上一行多出的<?xml version="1.0"?>
值得一提的是,这些配置都可以在hadoop-2.6.5\share\doc\hadoop\index.html里面找到,最好用IE浏览器打开,否则可能不识别。
在windows上用IE浏览器打开hadoop-2.6.5\share\doc\hadoop\index.html,点击进入core-default.xml
可以看到,hadoop.tmp.dir的默认配置为/tmp/hadoop-${user.name},即在Linux的临时文件下保存,所以我们要修改配置

要记住:
core-default.xml中的所有配置都可以在core-site.xml中进行配置。hdsf-default.xml中的所有配置都可以在hdfs-site.xml中进行配置。
8、配置hdfs-site.xml
1 | [root@layne1 hadoop]# pwd |
加入以下内容:
1 | <configuration> |
9、配置slaves
这里是配置datanode结点
1 | [root@layne1 hadoop]# pwd |
即在slaves输入layne1。
10、格式化hadoop
下面可以看到,第7步配置的临时目录位置不存在
1 | [root@layne1 hadoop]# ls /var/layne/hadoop/pseudo |
现在输入
1 | hdfs namenode -format |
再次查看日志
1 | [root@layne1 hadoop]# ls /var/layne/hadoop/pseudo |
11、启动hadoop
输入以下命令启动hadoop
1 | start-dfs.sh |
启动过程如下:
1 | [root@layne1 current]# start-dfs.sh |
12、查看hadoop进程
输入jps
1 | [root@layne1 current]# jps |
说明进程都正常启动了,然后网页访问:
进入文件系统
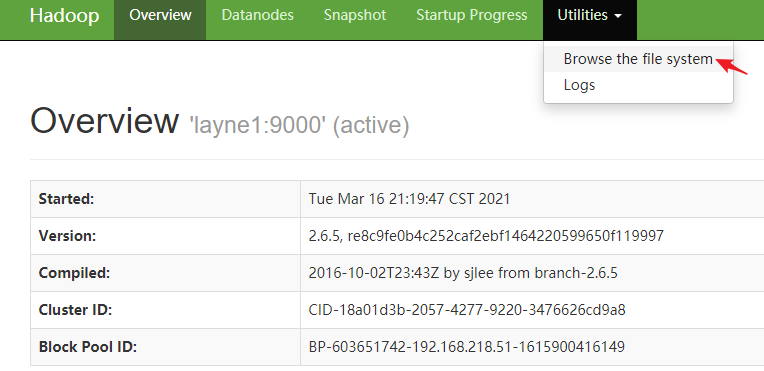
下图可以看出,文件系统为空
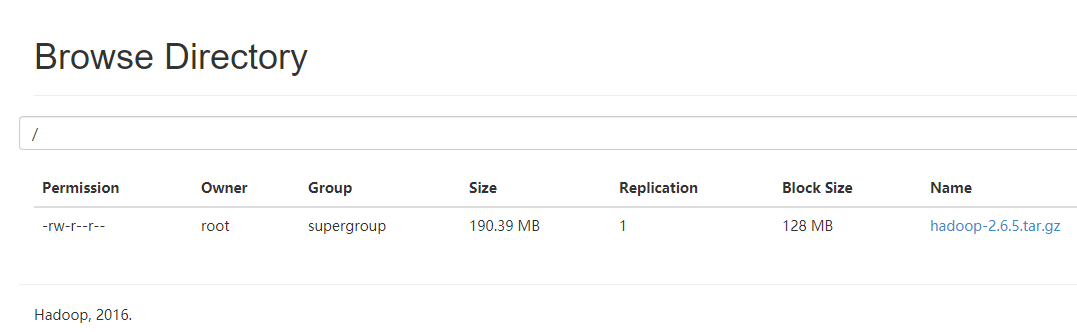
13、上传文件
我们试着上传一个文件
1 | [root@layne1 apps]# ll |
现在可以看到上传的文件
点击文件名称,可以看到该文件被分为两个block块,第一个block为128M(没有指定block,默认大小为128M)
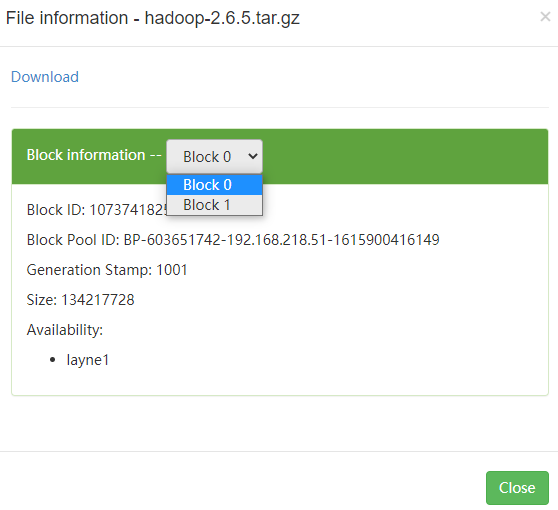
然后,我们自己生成一个文件
1 | [root@layne1 apps]# pwd |
上传生成的hh.txx文件,文件block块大小为1048576字节,重复数为1:
1 | hdfs dfs -D dfs.blocksize=1048576 -D dfs.replication=1 -put hh.txt / |
再次刷新,就能看到上传的文件了。
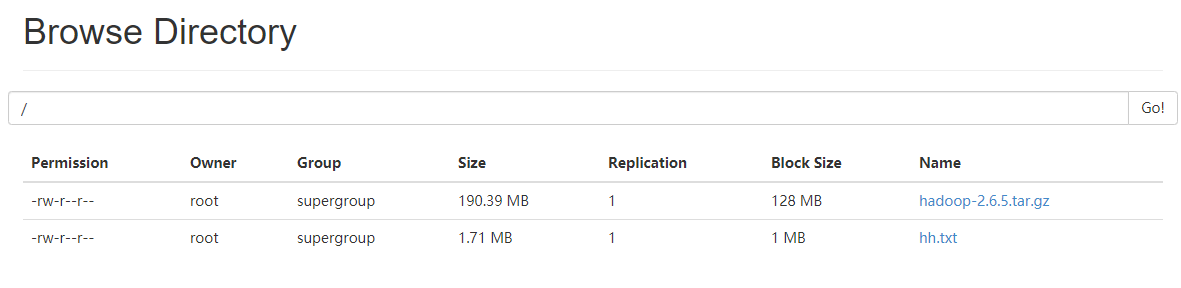
从上图可以看出,刚刚上传的hh.txx文件块大小为1M,这是因为1024x1024=1048576,dfs.blocksize单位是字节,即bytes,1KB=1024bytes,所以1024x1024bytes=1048576bytes=1024KB=1M
-D dfs.replication=1指定副本数为1,如果不指定,默认按照第8步dfs.replication配置的副本数。一般来说,可以将不重要的文件的副本数设置小一点。
在上传文件时,-D dfs.blocksize和-D dfs.replication可以不指定,所以上传文件的格式为:
1 | hdfs dfs -put 被上传的文件全路径名或相对路径名 放置的hdfs目录 |
比如,hdfs dfs -put test.txt /a/b,就是将当前目录下的test.txt文件,上传到hdfs的a/b目录下,这个前提是a/b目录一定要存在。
14、查看hdfs中的文件
1 | [root@layne1 apps]# hdfs dfs -ls / |
当然,也可以在浏览器中查看。
15、查看hadoop存储目录
1 | [root@layne1 dfs]# pwd |
查看生成的块
1 | [root@layne1 subdir0]# pwd |
查看datanode相关信息
1 | [root@layne1 current]# pwd |
16、关闭hadoop
1 | stop-dfs.sh |