正则表达式grep详解
我总结了多种grep常用正则表达式及其组合,能够满足大多数使用场景。
我们先来看看正则表达式的匹配符:
-
\转义字符\+ \< \> -
.匹配任意单个字符 -
[1234abc],[^1234],[1-5],[a-d]字符序列单字符占位 -
^行首^.k -
$行尾.k$ -
\<,\>,\<abc,abc\>,\<are\>单词首尾边界 okhelloworld ok hello world -
|连接操作符,并集(\<are\>)| (\<you\>) -
(,)选择操作符 -
\n反向引用
重复操作符:
*匹配0到多次?匹配0到1次+匹配1到多次{n}匹配n次{n,}匹配n到多次{m,n}匹配m到n次
先给出本文中的全部命令及其解释:
grep "after" profile查找文件内的包含"after"的行grep -n "after" profile查找文件内的包含"after"的行,并查看匹配行所在文档的行号。grep -n "after" profile | grep "then"在包含"after"的行中查找含有"then"的行grep -v -n "after" profile查找不包含after的行,并显示行号grep "a*re" hello.txt这里的*表示前面a出现0到多次,表示匹配如are aare xred的行grep "a.re" hello.txt这里的.表示匹配任意单个字符grep -E "a+re" hello.txt这里的+表示a有一到多个grep "a\+re" hello.txt这里有\+就不需要-E选项了grep "[b-d]" hello.txt匹配包含bcd中任意一个字符的行grep -v "[b-d]" hello.txt匹配不包含bcd中任意一个字符的行grep "?" hello.txt查找带问号的行grep "a.re" hello.txt这里的.占一个位置,匹配任意字符grep "..re" hello.txt匹配re前面有两个任意字符的行grep "[xz]k" hello.txt匹配带有zk和xk的行grep -v '[xz]k' hello.txt匹配不带有zk和xk的行grep "\<[zx]k" hello.txt匹配含有以zk和xk为开头的单词的行grep "^.k" hello.txt匹配每一行的第二个字符一定得是k的行(行头)grep ".k$" hello.txt匹配以k结尾的行(行尾),该行最少两个字符,最后一个是kgrep "\<are\>" hello.txt匹配包含单词are的行grep "\<are" hello.txt匹配以are为开头的单词所在的行grep "re\>" hello.txt匹配(一个单词的)单词尾grep -E "are|you" hello.txt匹配包含are或者you的行,满足其中任意条件(are或you)就会匹配。grep are hello.txt | grep you | grep ok必须同时满足三个条件(are、you和ok)才匹配。grep "\<a*re\>" hello.txt命令中的*表示(a)0到多次,即匹配单词以a字符开头,或者不以a字符开头,且以re结尾的行。grep "\<a*re\>" hello.txt等同于grep -E "(\<a*re\>)" hello.txtgrep -E "a{3}" hello.txt匹配有3个重复a的行grep -E "a+" hello.txt匹配含有一个或多个a的行,等同于grep "a\+" hello.txtgrep -E "a?" hello.txt匹配出现0或1次a的行,等同于grep "a\?" hello.txtgrep -E "*" hello.txt匹配任意字符,即匹配全部内容
后面是上面命令的执行过程。
现在来试试吧!
1 | [root@layne tdir]# cp /etc/profile . |
-v表示不包含的行
1 | [root@layne tdir]# grep -v -n "after" profile # 不包含after的行,并显示行号 |
再尝试更多的例子!
创建hello.txt,内容为:
1 | hello world |
匹配are aare xre,0到多个a字符
1 | [root@layne tdir]# grep "a*re" hello.txt # `*` 表示前面a出现0到多次 |
匹配“a任意单个字符re”
1 | [root@layne tdir]# grep "a.re" hello.txt #`.` 表示匹配任意单个字符 |
匹配a一个到多个任意字符re
1 | [root@layne tdir]# grep "a+re" hello.txt |
但是,发现查询不出来,这是为什么?
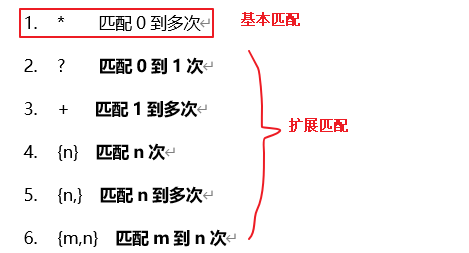
上图第1个是基本匹配,第2~6个是扩展匹配
grep命令默认处于基本工作模式下,加上-E 选项让grep工作于扩展模式
这样就可以解决上述问题来匹配a一个到多个任意字符re了:
1 | [root@layne tdir]# grep -E "a+re" hello.txt |
所以,在基本工作模式下,?,+,{,|,(,)这些符号就丢失了意义,需要加-E 选项让grep工作于扩展模式才能生效,或者前面加上\也能生效。
[a-d]匹配abcd中的一个
匹配包含bcd中任意一个字符的行**(两边都是闭区间)**和 不包含bcd中任意一个字符的行
1 | [root@layne tdir]# grep "[b-d]" hello.txt #匹配包含bcd中任意一个字符的行 |
查找带问号的行:
1 | [root@layne tdir]# grep "?" hello.txt |
.占一个位置,匹配任意字符
1 | [root@layne tdir]# grep "a.re" hello.txt |
匹配带有zk和xk的行 和没不带有zk和xk的行
1 | [root@layne tdir]# grep "[xz]k" hello.txt # 匹配带有zk和xk的行 |
匹配含有以zk和xk为开头的单词的行
1 | [root@layne tdir]# grep "\<[zx]k" hello.txt |
匹配第二个字符一定得是k的行(行头)
1 | [root@layne tdir]# grep "^.k" hello.txt |
匹配以k结尾的行(行尾)
1 | [root@layne tdir]# grep ".k$" hello.txt #该行最少两个字符,最后一个是k |
匹配单词边界(匹配一个单词)
1 | [root@layne tdir]# grep "\<are\>" hello.txt #匹配包含单词are的行 |
同时匹配多个关键字–或关系
1 | [root@layne tdir]# grep -E "are|you" hello.txt #匹配包含are或者you的行,满足其中任意条件(are或you)就会匹配。 |
同时匹配多个关键字–与关系
使用管道符连接多个 grep ,间接实现多个关键字的与关系匹配:
1 | [root@layne tdir]# grep are hello.txt | grep you | grep ok #必须同时满足三个条件(are、you和ok)才匹配。 |
grep "\<a*re\>" hello.txt 命令中的*表示(a)0到多次,即匹配单词以a字符开头,或者不以a字符开头,且以re结尾的行。
1 | [root@layne tdir]# grep "\<a*re\>" hello.txt |
另外,grep "\<a*re\>" hello.txt 等同于 grep -E "(\<a*re\>)" hello.txt
1 | [root@layne tdir]# grep -E "(\<a*re\>)" hello.txt |
grep -E "a{3}" hello.txt 匹配该行中3个a重复的
1 | [root@layne tdir]# grep -E "a{3}" hello.txt |
匹配一个到多个a :grep -E "a+" hello.txt 或grep "a\+" hello.txt
匹配0到1次a:grep -E "a?" hello.txt 或 grep "a\?" hello.txt
匹配任意字符:grep -E "*" hello.txt (即匹配全部内容)