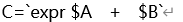Linux中的bash语法,主要介绍bash的io、变量、分支、循环等基本操作。
shell就是一个bash程序(进程),就是一个解释器,启动器
脚本本质:
#!/bin/bash
#!/usr/bin/python
上面的不是普通的注释,是你用./执行的时候,默认走的哪一个解释器
用bash test.sh执行的时候,是不看第一行的#!/bin/bash或#!/usr/bin/python ,直接用bash解释器。
同样的,用sh test.sh执行的时候也一样,其直接用sh解释器。
但是,用./ test.sh执行的时候,要看第一行,然后选择走哪一个解释器。
脚本读取(或解释执行)方式常用的有五种:
bash filenamesh filename./filenamesource filename. filename
说明: ./*.sh的执行方式等价于sh ./*.sh或者bash ./*.sh,此三种执行脚本的方式都是重新启动一个子shell,在子shell中执行此脚本。
source ./*.sh和 . ./*.sh的执行方式是等价的,即两种执行方式都是在当前shell进程中执行此脚本,而不是重新启动一个子shell执行。
一个重要的点:父shell进程中没有被export导出的变量(即非环境变量)是不能被子shell进程继承的,但是在父进程中被export的变量可以被子shll进程使用。子shell进程中的所有变量(无论是否被export)都不能被父进程使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 [root@layne ~] [root@layne ~] 1852 [root@layne ~] init(1)─┬─auditd(899)───{auditd}(900) ├─crond(1312) ├─mingetty(1338) ├─mingetty(1340) ├─mingetty(1342) ├─mingetty(1344) ├─mingetty(1346) ├─mingetty(1348) ├─ntpd(973) ├─rsyslogd(915)─┬─{rsyslogd}(917) │ ├─{rsyslogd}(919) │ └─{rsyslogd}(920) ├─sshd(965)───sshd(1030)───bash(1219)───bash(1852)───pstree(1862) └─udevd(354)───udevd(640) [root@layne ~] exit [root@layne ~] 1219 [root@layne ~] init(1)─┬─auditd(899)───{auditd}(900) ├─crond(1312) ├─mingetty(1338) ├─mingetty(1340) ├─mingetty(1342) ├─mingetty(1344) ├─mingetty(1346) ├─mingetty(1348) ├─ntpd(973) ├─rsyslogd(915)─┬─{rsyslogd}(917) │ ├─{rsyslogd}(919) │ └─{rsyslogd}(920) ├─sshd(965)───sshd(1030)───bash(1219)───pstree(1863) └─udevd(354)───udevd(640)
可以看到,当我们用ssh连接虚拟机时,会启动sshd进程,进入bash命令行界面后,会启动bash进程,这个bash进程是sshd进程的子进程,当我们在命令行中输入bash会启动一个新的bash进程,这个新的bash进程是之前bash进程的子进程。
现在我们来验证:父shell进程中没有被export导出的变量(即非环境变量)是不能被子shell进程继承的,但是在父进程中被export的变量可以被子shll进程使用。
1 2 3 4 5 6 7 8 [root@layne ~] [root@layne ~] [root@layne ~] layne,24 [root@layne ~] [root@layne ~] [root@layne ~] layne,
可以看到,在子进程的bash,只能输出被export导出的变量(即环境变量),不能输出普通变量。
还有一个重要点:子shell进程中的所有变量(无论是否被export)都不能被父进程使用 。验证如下:
1 2 3 4 5 6 7 [root@layne bashdir] [root@layne bashdir] [root@layne bashdir] lazz [root@layne bashdir] exit [root@layne bashdir]
另外,在.sh文件的开头一般输入下列中的一个:
用于指定该脚本由哪个程序负责解释执行。
现在我们创建两个文件mysh.sh和mysh1.sh
mysh.sh内容
1 2 3 #!/bin/bash echo "hello mysh" echo $$
mysh1.sh内容
1 2 3 4 #!/bin/bash echo "hello mysh1" echo $$pstree -p
下面是执行过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 [root@layne bashdir] total 8 -rwxr-xr-x 1 root root 49 Feb 9 16:27 mysh1.sh -rwxr-xr-x 1 root root 39 Feb 9 16:27 mysh.sh [root@layne bashdir] [root@layne bashdir] [root@layne bashdir] total 8 -rw-r--r-- 1 root root 49 Feb 9 16:27 mysh1.sh -rw-r--r-- 1 root root 39 Feb 9 16:27 mysh.sh [root@layne bashdir] hello mysh 1219 [root@layne bashdir] hello mysh1 1219 init(1)─┬─auditd(899)───{auditd}(900) ├─crond(1312) ├─mingetty(1338) ├─mingetty(1340) ├─mingetty(1342) ├─mingetty(1344) ├─mingetty(1346) ├─mingetty(1348) ├─ntpd(973) ├─rsyslogd(915)─┬─{rsyslogd}(917) │ ├─{rsyslogd}(919) │ └─{rsyslogd}(920) ├─sshd(965)───sshd(1030)───bash(1219)───pstree(1890) └─udevd(354)───udevd(640) [root@layne bashdir] init─┬─auditd───{auditd} ├─crond ├─6*[mingetty] ├─mysqld_safe───mysqld───27*[{mysqld}] ├─ntpd ├─rsyslogd───3*[{rsyslogd}] ├─sshd───sshd───bash───pstree └─udevd───udevd [root@layne bashdir] -bash: ./mysh.sh: Permission denied [root@layne bashdir] [root@layne bashdir] hello mysh 1894 [root@layne bashdir] [root@layne bashdir] hello mysh1 1898 init(1)─┬─auditd(899)───{auditd}(900) ├─crond(1312) ├─mingetty(1338) ├─mingetty(1340) ├─mingetty(1342) ├─mingetty(1344) ├─mingetty(1346) ├─mingetty(1348) ├─ntpd(973) ├─rsyslogd(915)─┬─{rsyslogd}(917) │ ├─{rsyslogd}(919) │ └─{rsyslogd}(920) ├─sshd(965)───sshd(1030)───bash(1219)───mysh1.sh(1898)───pstree(1899) └─udevd(354)───udevd(640)
可以发现:
当前shell执行脚本:source mysh.sh ,不需要执行权限就可以执行
子进程执行:bash mysh.sh或者./mysh.sh,需要该文件具有可执行权限才能执行
.sh文件中的函数格式为:
在下面的例子中会用到。
程序自身都有I/O
例如:
1 ls / /hello 1> log.out 2> log.err
上面命令把正确的输出放在log.out里面,把错误的输出放在log.err里面。
下面,我们看几个常用场景
(1)输出重定向: 重定向从左到右绑定
1 2 3 4 5 6 7 8 ls / /hello 2>&1 1> mylog.log ls / /hello 1> mylog1.log 2>&1 ls / /hello >& mylog2.log ls / /hello &> mylog3.log
(2)现在,我们创建rd.sh文件,内容如下:
1 2 3 4 5 #!/bin/bash read -p "请输入一个整数:" numecho $num read -p "再输入一个数:" echo $REPLY
执行结果:
1 2 3 4 5 6 [root@layne bashdir] [root@layne bashdir] 请输入一个整数:123 123 再输入一个数:45 45
sh -x rd.sh 检查你写的脚本,执行到哪一步,把执行的过程打出来
1 2 3 4 5 6 7 8 9 [root@layne bashdir] + read -p $'\350\257\267\350\276\223\345\205\245\344\270\200\344\270\252\346\225\264\346\225\260\357\274\232' num 请输入一个整数:123 + echo 123 123 + read -p $'\345\206\215\350\276\223\345\205\245\344\270\200\344\270\252\346\225\260\357\274\232' 再输入一个数:45 + echo 45 45
(3)将标准输入重定向到字符串,read读取后赋值给指定的变量:
1 2 3 [root@layne bashdir] [root@layne bashdir] hello
上面 <<<将标准输入重定向到字符串
(4)cat 0<<CATEOF用在脚本中用于向控制台打印n行,比如:
1 2 3 4 5 6 7 8 [root@layne bashdir] > aaaaa > bbbbb > ccccc > CATEOF aaaaa bbbbb ccccc
创建catof.sh文件,内容为:
1 2 3 4 5 #!/bin/bash cat 0<<CATEOF 这里有一个bug 这个bug是index out of bounds exception CATEOF
执行:
1 2 3 4 [root@layne bashdir] [root@layne bashdir] 这里有一个bug 这个bug是index out of bounds exception
(5)exec:使用指定的命令替换当前shell命令。
以读写方式打开到www.baidu.com的80端口的tcp连接
1 2 3 4 5 6 7 8 9 [root@layne bashdir] [root@layne bashdir] [root@layne bashdir] HTTP/1.0 200 OK Accept-Ranges: bytes Cache-Control: no-cache Content-Length: 14615 Content-Type: text/html ...
echo的-e选项含义为:激活转义字符。使用-e选项时,若字符串中出现以下字符,则特别加以处理,而不会将它当成一般文字输出:
\a 发出警告声;\b 删除前一个字符;\c 最后不加上换行符号;\f 换行但光标仍旧停留在原来的位置;\n 换行且光标移至行首;\r 光标移至行首,但不换行;\t 插入tab;\v 与\f相同;\\ 插入\字符;\nnn 插入nnn(八进制)所代表的ASCII字符;
echo -e "GET / HTTP/1.0\n" >&8 表示重定向到8文件描述符
cat <&8 从文件描述符8读取信息
看下面的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@layne bashdir] [root@layne bashdir] 99 [root@layne bashdir] > myvar=99 > echo $myvar > } [root@layne bashdir] [root@layne bashdir] 99 [root@layne bashdir] 99 [root@layne bashdir] [root@layne bashdir] sxt [root@layne bashdir] [root@layne bashdir] sxtisnothere [root@layne bashdir] sxt isnotthere [root@layne bashdir] {sxt}isnotthere
只能用于函数
local var=100 定义一个局部变量
看例子:
1 2 3 4 5 6 7 8 9 10 [root@layne bashdir] [root@layne bashdir] [root@layne bashdir] > local myvar=101 > echo $myvar > } [root@layne bashdir] [root@layne bashdir]
继续往下看:
1 2 3 4 5 6 7 8 9 10 11 [root@layne bashdir] > a=1 > local b=2 > echo "a = $a " > echo "b = $b " > } [root@layne bashdir] a = 1 b = 2 [root@layne bashdir] 1,
上面,a是本地变量,b是局部变量,本地变量生命周期跟当前shell一样,局部变量的声明周期在一个函数内,函数执行完,局部变量就消失了。
直接看例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [root@layne bashdir] > echo $1 > } [root@layne bashdir] [root@layne bashdir] hello [root@layne bashdir] > echo $4 > } [root@layne bashdir] [root@layne bashdir] d [root@layne bashdir] > echo $13 > } [root@layne bashdir] 13 [root@layne bashdir] a3 [root@layne bashdir] > echo ${13} > } [root@layne bashdir] d
可以看到,$n为函数的第n个位置变量(第n个参数),${13}是函数的第13个参数,不能写为$13
再来看一个例子,创建文件mysh1.h,内容如下:
1 2 3 4 #!/bin/bash echo $1 echo $2 echo ${10}
执行结果:
1 2 3 4 [root@layne bashdir] a b 8
$#:位置参数个数$*:参数列表,所有的参数作为一个字符串,以空格隔开$@:参数列表,双引号引用为单独的字符串,所有的参数作为单个的字符串,以空格隔开$$:当前shell的PID$?:上一个命令的退出状态0:成功
其他:失败
例子:创建mysh2.sh
1 2 3 4 5 6 #!/bin/bash echo "number of args:$# " echo "string of args:$*" echo "args:$@ " echo "current pid:$$" pstree -p
执行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 [root@layne bashdir] [root@layne bashdir] number of args:7 string of args:a b 1 2 3 4 5 args:a b 1 2 3 4 5 current pid:2033 init(1)─┬─auditd(899)───{auditd}(900) ├─crond(1312) ├─mingetty(1338) ├─mingetty(1340) ├─mingetty(1342) ├─mingetty(1344) ├─mingetty(1346) ├─mingetty(1348) ├─ntpd(973) ├─rsyslogd(915)─┬─{rsyslogd}(917) │ ├─{rsyslogd}(919) │ └─{rsyslogd}(920) ├─sshd(965)───sshd(1945)───bash(1947)───mysh2.sh(2033)───pstree(2034) └─udevd(354)───udevd(640) [root@layne bashdir] number of args:7 string of args:a b 1 2 3 4 5 args:a b 1 2 3 4 5 current pid:1947 init(1)─┬─auditd(899)───{auditd}(900) ├─crond(1312) ├─mingetty(1338) ├─mingetty(1340) ├─mingetty(1342) ├─mingetty(1344) ├─mingetty(1346) ├─mingetty(1348) ├─ntpd(973) ├─rsyslogd(915)─┬─{rsyslogd}(917) │ ├─{rsyslogd}(919) │ └─{rsyslogd}(920) ├─sshd(965)───sshd(1945)───bash(1947)───pstree(2036) └─udevd(354)───udevd(640)
$?用于获取上一个命令的退出状态
1 2 3 4 5 6 7 8 9 10 11 [root@layne bashdir] [root@layne bashdir] [root@layne bashdir] /root is dir [root@layne bashdir] [root@layne bashdir] [root@layne bashdir] 0 [root@layne bashdir] [root@layne bashdir] 1
Bash提供了一维数组变量。任何变量都可以作为一个数组;内建命令 declare 可以显式地定义数组。数组的大小没有上限(初始创建多大的数组,可以超过这个大小继续往后赋值) ,也没有限制在连续对成员引用和赋值时有什么要求。数组以整数为下标,从0开始。
如果变量赋值时使用语法 name[subscript]=value,那么就会自动创建数组。 subscript 被当作一个算术表达式,结果必须是大于等于 0 的值。数组赋值可以使用复合赋值的方式,形式是 name=(value1 value2 ... valuen),这里每个 value 的形式都是[subscript]=string。string 必须出现。如果出现了可选的括号和下标,将为这个下标赋值,否则被 赋值的元素的下标是语句中上一次赋值的下标加一。下标从 0 开始。这个语法也被内建命令 declare 所接受。单独的数组元素可以用上面介绍的语法 name[subscript]=value 来赋值
数组的任何元素都可以用 ${name[subscript]} 来引用。花括号是必须的,以避免和路径扩展冲突。如果subscript 是 @ 或是 *,它扩展为 name 的所有成员。这两种下标只有在双引号中才不同。在双引号中,${name[*]} 扩展为一个词,由所有数组成员的值组成 ,用特殊变量 IFS 的 第 一 个 字 符 分 隔;${name[@]}将 name 的每个成员 扩展为一个词。如果数组没有成员,${name[@]} 扩展为空串。这种不同类似于特殊参数 *和@ 的扩展 (参见上面的 Special Parameters 段落)。${#name[subscript]} 扩展为 ${name[subscript]} 的长度。如果 subscript 是 * 或者是 @,扩展结果是数组中元素的个数。引用没有下标数组变量等价于引用元素 0。
内建命令 unset 用于销毁数组 。unset name[subscript] 将销毁下标是 subscript 的 元 素 。 unset name, 这里 name 是一个数组,或者 unset name[subscript], 这里 subscript 是 * 或者是 @,将销毁整个数组。 内建命令 declare, local, 和 readonly 都能接受-a 选项,从而指定一个数组。内建命令 read 可 以接受 -a 选项,从标准输入读入一列词来为数组赋值。内建命令 set 和 declare 使用一种可以重用为输入的格式来显示数组元素。
1 2 3 4 5 6 7 8 9 [root@layne bashdir] [root@layne bashdir] a [root@layne bashdir] b [root@layne bashdir] a b c [root@layne bashdir] a b c
注意:echo $sxt[1] 是错误的写法
直接看例子:
1 2 3 4 5 6 [root@layne bashdir] [root@layne bashdir] 9 [root@layne bashdir] ok [root@layne bashdir]
管道两边的命令在当前shell的两个子进程中执行。
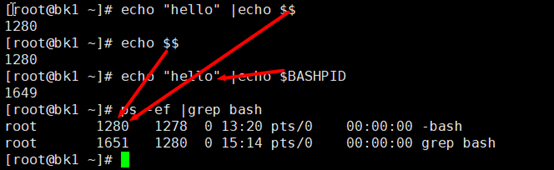
$$和$BASHPID的区别
$$是在哪个进程中执行命令,该值就是哪个shell进程的PIDecho "hello"| echo $BASHPID 这里的id是前面执行echo "hello"的shell的id,而echo $$ 是当前shell的id
另外,我们创建一个test.sh再来测试一下,test.sh内容如下:
1 2 3 4 #!/bin/bash echo "\$\$ value:$$" echo "BASHPID value:$BASHPID " pstree -p
执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@layne bashdir] [root@layne bashdir] $$ value:2208 BASHPID value:2208 init(1)─┬─auditd(899)───{auditd}(900) ├─crond(1312) ├─mingetty(1338) ├─mingetty(1340) ├─mingetty(1342) ├─mingetty(1344) ├─mingetty(1346) ├─mingetty(1348) ├─ntpd(973) ├─rsyslogd(915)─┬─{rsyslogd}(917) │ ├─{rsyslogd}(919) │ └─{rsyslogd}(920) ├─sshd(965)───sshd(1945)───bash(1947)───test.sh(2208)───pstree(2209) └─udevd(354)───udevd(640)
可以看到,在子进程执行的时候,$$和$BASHPID 输出的都是当前进程的ID
另外,再创建test1.sh
1 2 3 4 5 6 7 8 9 10 11 12 #!/bin/bash echo "\$\$ outside of subshell = $$" echo "\$BASH_SUBSHELL outside of subshell = $BASH_SUBSHELL " echo "\$BASHPID outside of subshell = $BASHPID " echo ( echo "\$\$ inside of subshell = $$" echo "\$BASH_SUBSHELL inside of subshell = $BASH_SUBSHELL " echo "\$BASHPID inside of subshell = $BASHPID " )
执行:
1 2 3 4 5 6 7 8 9 [root@layne bashdir] [root@layne bashdir] $$ outside of subshell = 2214 $BASH_SUBSHELL outside of subshell = 0$BASHPID outside of subshell = 2214$$ inside of subshell = 2214 $BASH_SUBSHELL inside of subshell = 1$BASHPID inside of subshell = 2215
我的理解: $$表示脚本文件在其下运行的进程ID。对于任何给定的脚本,当它运行时,它将只有一个“主”进程标识 。不管您调用了多少个子shell,$$将始终返回与脚本关联的第一个进程标识。 $BASHPID将显示当前bash实例的进程ID,因此在子shell中它将与可能调用它的**“顶级”**bash不同。$BASH_SUBSHELL 表示你所在的“subshell级别”。如果你不在任何子级别,则级别为零。如果你在主程序中启动子shell,则该子shell级别为1。如果在该子shell内启动子shell,则级别为2,依此类推。
单引号将其中的内容都作为了字符串来,忽略所有的命令和特殊字符,类似于一个字符串的用法
双引号与单引号的区别在于其可以包含特殊字符(单引号直接输出内部字符串,不解析特殊字符;双引号内则会解析特殊字符),包括', ", $, \,如果要忽略特殊字符,就可以利用\来转义,忽略特殊字符,作为普通字符输出:
1 2 3 4 5 6 7 [root@layne bashdir] [root@layne bashdir] $var [root@layne bashdir] 3 [root@layne bashdir] Here "this is a string" is a string
命令替换允许我们将shell命令的输出赋值给变量 。它是脚本编程中的一个主要部分。
命令替换会创建子shell进程来运行相应的命令。子shell是由运行该脚本的shell所创建出来的一个独立的子进程,由该子进程执行的命令无法使用(父)脚本中所创建的变量(除非是export的环境变量)。
反引号提升扩展优先级,先执行反引号的内容,再执行其他的 。
1 2 3 4 5 [root@layne bashdir] -bash: hello: command not found [root@layne bashdir] [root@layne bashdir] hello
再来看一个例子:
1 2 3 4 5 6 7 [root@layne tdir] root@layne2's password: test.txt 100% 20 0.0KB/s 00:00 [root@layne tdir]# scp /root/tdir/log.txt layne2:`pwd` # 作用同上,相当于先输入pwd,把pwd的返回结果赋值给`pwd` root@layne2' s password: log.txt 100% 12 0.0KB/s 00:00 [root@layne tdir]
command1 && command2
n 如果command1退出状态是0(0代表正确),则执行command2
command1 || command2
n 如果command1的退出状态不是0,则执行command2
1 2 3 4 5 6 7 8 9 10 [root@layne2 ~] 文件夹/hello不存在 [root@layne2 ~] 文件夹/bin存在 [root@layne2 ~] [root@layne2 ~] bin boot dev etc home lib lib64 lost+found media mnt opt proc root sbin selinux srv sys tmp usr var ok [root@layne2 ~] bin boot dev etc home lib lib64 lost+found media mnt opt proc root sbin selinux srv sys tmp usr var
(1)算术表达式
let 算数运算表达式
$[算术表达式]
$((算术表达式))
C=$((A+B))C=$((A+B+1)) #在原来结果的基础上再加1
expr算术表达式
表达式中各操作数及运算符之间要有空格,同时要使用命令引用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@layne2 ~] [root@layne2 ~] [root@layne2 ~] [root@layne2 ~] 3 [root@layne2 ~] [root@layne2 ~] 4 [root@layne2 ~] [root@layne2 ~] 2 [root@layne2 ~] [root@layne2 ~] 5
(2)条件表达式
[ 表达式 ]
test 表达式
[[ 表达式 ]]
1 2 3 4 5 6 7 test 3 -gt 2 && echo ok等价于 [ 3 -gt 2 ] && echo ok test 3 -gt 8 && echo ok等价于 [ 3 -gt 8 ] && echo ok
单分支结构
1 2 3 4 5 6 7 8 9 10 if [ 条件判断 ] then //命令 fi 或者 if [ 条件判断 ]; then 条件成立执行,命令; fi # 将if反过来写,就成为fi,结束if语句
双分支结构
1 2 3 4 5 if [ 条件1 ];then 条件1成立执行,指令集1 else 条件1不成执行指令集2; fi
多分支结构
1 2 3 4 5 6 7 if [ 条件1 ];then 条件1成立,执行指令集1 elif [ 条件2 ];then 条件2成立,执行指令集2 else 条件都不成立,执行指令集3 fi
使用[命令判断
1 2 3 4 5 6 7 8 if [ 3 -gt 2 ]; then echo ok fi if [ 3 -gt 2 ]then echo ok fi
示例:
创建sh01.sh
1 2 3 4 5 6 7 8 9 10 11 #!/bin/bash a=20 if [ $a -gt $1 ];then echo "你输入的数字太小" elif [ $a -eq $1 ];then echo "恭喜哈,数字相等" else echo "你输入的数字太大" fi
执行:
1 2 3 4 5 6 7 8 9 10 11 12 [root@layne bashdir] 你输入的数字太大 [root@layne bashdir] 恭喜哈,数字相等 [root@layne bashdir] 你输入的数字太小 [root@layne bashdir] 你输入的数字太大 [root@layne bashdir] ./sh01.sh: line 3: [: 20: unary operator expected ./sh01.sh: line 6: [: 20: unary operator expected 你输入的数字太大
注意:if和中括号之间要有空格,中括号和条件表达式之间要有空格
;和then之前有空格没空格都可以
1 2 3 4 5 6 7 8 9 10 case $变量名称 in “值1") 程序段1 ;; “值2" ) 程序段2 ;; *) exit 1 ;; esac
上面*类似java里面的default
exit 1 是echo $?获取到的返回值,exit 0代表正确的返回,exit 1代表错误的返回结果
案例:判断用户输入的是哪个数,1-7显示输入的数字,1显示 Mon,2 :Tue,3:Wed,4:Thu,5:Fir,6-7:weekend,其它值的时候,提示:please input [1,7],该如何实现?
创建sh02.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 #!/bin/bash read -p "please input a number[1,7]:" numcase $num in 1) echo "Mon" ;; 2) echo "Tue" ;; 3) echo "Wed" ;; 4) echo "Thu" ;; 5) echo "Fir" ;; [6-7]) echo "weekend" ;; *) echo "please input [1,7]" ;; esac 或者 #!/bin/bash case $1 in 1) echo "Mon" exit 0 ;; 2) echo "Tue" exit 0 ;; 3) echo "Wed" exit 0 ;; 4) echo "Thu" exit 0 ;; 5) echo "Fir" exit 0 ;; [6-7]) echo "weekend" exit 0 ;; *) echo "please input [1,7]" exit 1 ;; esac
执行:
1 2 3 4 5 6 7 [root@layne bashdir] [root@layne bashdir] please input a number[1,7]:5 Fir [root@layne bashdir] please input a number[1,7]:8 please input [1,7]
1 2 3 4 5 6 7 8 while [ condition ] ; do 命令 done 或者 while [ condition ] do 命令 done
注意:while也与中括号之间有空格
案例一:每隔两秒打印系统负载情况,如何实现?
创建while1.sh
1 2 3 4 5 6 #!/bin/bash while true do uptime sleep 2 done
执行:
1 2 3 4 5 6 [root@layne bashdir] [root@layne bashdir] 23:05:07 up 12:56, 1 user, load average: 0.00, 0.00, 0.00 23:05:09 up 12:56, 1 user, load average: 0.00, 0.00, 0.00 23:05:11 up 12:56, 1 user, load average: 0.00, 0.00, 0.00
案例二:使用while循环,编写shell脚本,计算1+2+3+…+100的和并输出,如何实现?
创建while2.sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #!/bin/bash sum=0 i=1 while [ $i -le 100 ] do sum=$((sum+i)) i=$((i+1)) done echo "the result of '1+2+3+...+100' is $sum " 或者: #!/bin/bash sum=0 i=1 while [ $i -le 100 ] do let sum=$sum +$i let i=$i +1 done echo "the result of '1+2+3+...+100' is $sum "
1 2 3 4 for 变量名 in 变量取值列表do 命令 done
案例1:创建for1.sh
1 2 3 4 5 #!/bin/sh for num in 1 2 3 4 do echo $num done
执行:
1 2 3 4 5 6 [root@layne bashdir] [root@layne bashdir] 1 2 3 4
使用大括号的方法:
1 2 3 4 5 6 [root@layne bashdir] 1 2 3 4 5 6 7 8 [root@layne bashdir] a b c d e f g h i j k l m n o p q r s t u v w x y z [root@layne bashdir] 10.13.20.1 10.13.20.2 10.13.20.3
编辑for1.sh
1 2 3 4 5 #!/bin/sh for num in {1..4} do echo $num done
案例2:使用seq –s 分隔符 起始 步长 终点
1 2 3 4 [root@layne bashdir] 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54 56 58 60 62 64 66 68 70 72 74 76 78 80 82 84 86 88 90 92 94 96 98 100 [root@layne bashdir] 1 2 3 4 5
创建for2.sh
1 2 3 4 5 #!/bin/sh for num in `seq -s " " 1 1 5`do echo $num done
注意:for后面``里面是执行的命令
执行for2.sh
1 2 3 4 5 6 7 [root@layne bashdir] [root@layne bashdir] 1 2 3 4 5
$IFS默认空格、制表符和换行符 都可以识别
for循环的时候 空格、制表符和换行符都可以识别(在不改$IFS情况下),如果要改变$IFS,让它识别这三个中的一个,比如让它只识别换行符,把IFS=$'\n',这样一行一个循环,即一次一行来循环操作,不用管一行里面的空格或制表符。
du -a 列出所有的文件与目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@layne bashdir] 32 ./rdir 120 . [root@layne bashdir] 4 ./rdir/a.sh 4 ./rdir/test.txt 32 ./rdir 4 ./mylog2.log 4 ./log.err 4 ./mylog.log 4 ./mylog3.log 4 ./nohup.out 4 ./test.sh 4 ./my.log 4 ./sh01.sh ...
步骤一:
思路:使用du命令加-a遍历用户指定目录($1获取)的所有文件,使用管道将结果传递给sort,让sort使用数值序倒序排序,依次输出各个条目。
1 2 3 4 5 6 7 8 #!/bin/bash oldIFS=$IFS IFS=$'\n' for item in `du -a $1 | sort -nr`; do echo $item done IFS=$oldIFS
$1是第一个参数sort -nr :因为du输出的两列,第一列是大小,第二列是目录或文件,中间用制表符(\t)隔开,sort可以默认识别这种写法,并默把两列分开后用第一列排序,这里是缩写,全称为sort -t '\t' -k 1 -nr sort.txt
因为要获取最大的文件,需要改进
1 2 3 4 5 6 7 8 9 10 11 12 #!/bin/bash oldIFS=$IFS IFS=$'\n' for item in `du -a $1 | sort -nr`; do fileName=`echo $item | awk '{print $2}' ` if [ -f $fileName ]; then echo $fileName break fi done IFS=$oldIFS
awk默认也是识别制表符,换行符,空格等
awk '{print $2}'这是取第二列,不是文件的第二个参数
问题:
循环遍历文件每一行:流程控制语句 IFS
思路:
方案一 :
思路:定义一个计数器,使用for循环从文件内容按行获取元素,每个元素是一行,在for循环中递增计数器用于计行数
1 2 3 4 5 6 7 8 9 10 11 #!/bin/bash num=0 oldIFS=$IFS IFS=$'\n' for item in `cat $1 `; do echo $item ((num++)) done echo "line number is :$num " IFS=$oldIFS
解释:
1 for item in `cat $1 `; do
这里for循环可以识别换行符,所以可以遍历(即一行循环一次)
方案二:
思路:先使用wc数出总行数 ,然后使用带下标的for循环分页遍历该文件,打印出每行,最后打印出总行数。
注意:
1、cat $1 | wc -l:返回行数
2、如果for循环想要java的写法,则可以在for后面用两个((包起来 ,如for ((i=1;i<=lines;i++))
1 2 3 4 5 6 7 8 9 10 #!/bin/bash num=0 lines=`cat $1 | wc -l` hello=$1 for ((i=1;i<=lines;i++)); do line=`head -$i $hello | tail -1` echo $line ((num++)) done echo "line number is :$num "
方案三:
思路:将while的read标准输入重定向到文件file.txt,按行读取,每读一行,就打读到的行记录,同时计数器+1,最后得出总行数。
1 2 3 4 5 6 7 #!/bin/bash num=0 while read line ;do echo $line ((num++)) done < $1 echo "line number is : $num "
解释:>>和>都属于输出重定向,<属于输入重定向
while read line [linux] shell 学习 可参考:https://blog.csdn.net/qq_22083251/article/details/80484176
写的不错。
方案四:
使用管道命令,但是通过管道无法向父进程传递数据 (管道两边的命令在当前shell的两个子进程中执行 ),需要将结果数据写到文件中,运行结束后,将数据读出来即可
1 2 3 4 5 6 7 #!/bin/bash num=0 cat $1 | while read line; do echo $line ((num++)) done echo "line number is: $num " > $2