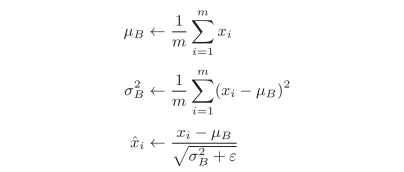一、前言
高光谱图像(Hyperspectral image,以下简称HSI)分类广泛应用于遥感图像的分析,随着深度学习和神经网络的兴起,越来越多的人使用二维CNN对HSI进行分类,而HSI分类性能却高度依赖于空间和光谱信息,由于计算复杂度增加,很少有人将三维CNN应用于HSI分类中。这篇 Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification构建一种混合网络(HybridSN)解决了HSI分类所遇到的问题,它首先用三维CNN提取空间-光谱的特征,然后在三维CNN基础上进一步使用二维CNN学习更多抽象层次的空间特征,这与单独使用三维CNN相比,混合的CNN模型既降低了复杂性,也提升了性能。经实验证明,使用HybridSN进行HSI分类,能够获得非常不错的效果。
二、高光谱图像
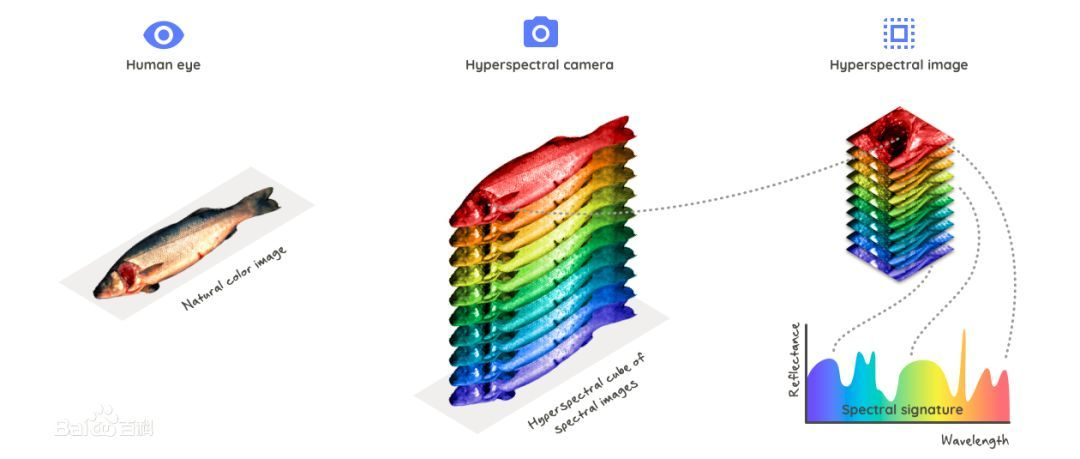
在进行高光谱图像分类之前,我认为有必要了解什么是高光谱图像。从计算机的角度来说,高光谱图像(Hyperspectral image)就是由多通道(几十甚至几百个)的数组构成的图像,每个像素点都有很多的数来描述,单个通道上的“灰度值”反映了被拍摄对象对于某一波段的光的反射情况。
我们知道,常见的RGB彩色图像只有三个通道,而高光谱图像有几十甚至几百个通道,所以高光谱图像包含包含更多的目标信息,利用高光谱图像进行目标的分类识别也必然比采用RGB图像具有更高的准确度。如下图所示,利用高光谱相机可以拍摄出由不同波长组成的空间立方体图像(即高光谱图像),用一个光谱曲线将其显示出来,横轴表示波长,纵轴表示反射系数,由于同一物体对不同波长的光反射因子不一样,因此利用高光谱图像更能反映出不同物体的差异性。

其实高光谱成像技术在很早以前就已经被广泛应用了,天上的卫星拍摄到的就是高光谱图像,通过分析每个像素点的光谱曲线,可以把不同地面目标对应的像素点分类,从而在高光谱图像中把地面、建筑物、草坪、江河等等区分开。
三、HybridSN模型
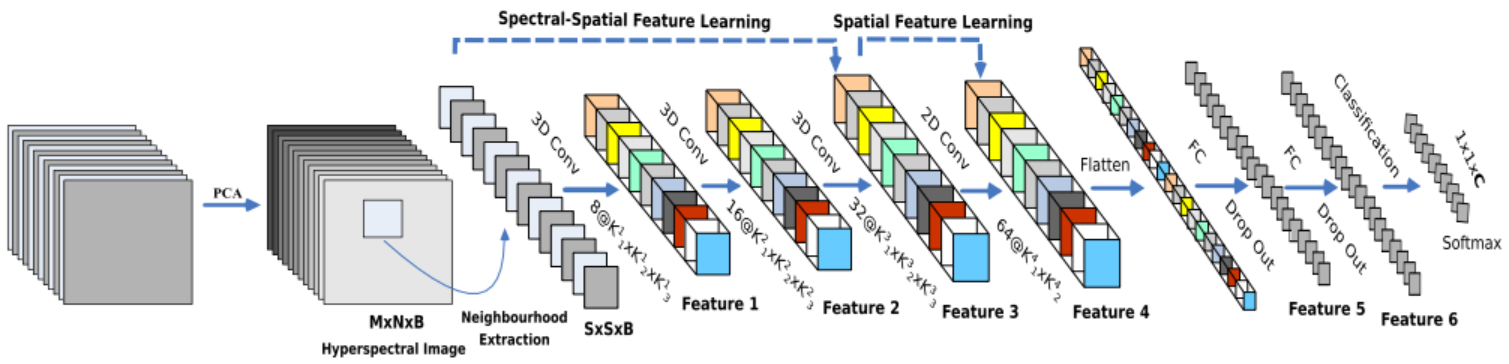
对于HSI分类问题,我们在提取空间信息的同时,也希望能获取到不同波长的光谱信息,而二维CNN是无法处理光谱信息的,也就无法提取到更具有判别性的特征图。幸运的是,三维CNN能够同时提取光谱和空间的特征,但代价是增加计算复杂度。为了充分发挥二维和三维CNN的优势,Swalpa Kumar Roy等人提出了HSI分类模型HybridSN,其模型图如下图所示,它由三个三维卷积、一个二维卷积和三个全连接层组成。
在HybridSN模型中,三维卷积核的尺寸分别为8×3×3×7×1(即图中K11=3 ,K21=3 ,K31=7)、16×3×3×5×8(即图中K12=3 ,K22=3 ,K32=5)和32×3×3×3×16(即图中K13=3 ,K23=3 ,K33=3),分别位于第一、第二和第三卷积层中。其中,16×3×3×5×8表示输入特征图的个数为8,输出特征图个数为16,三维卷积核大小为3x3x5,可理解为有两个空间维度和一个光谱维度。二维卷积在flatten之前被应用一次,它能有效的判别空间信息,也不会大量损失光谱信息,这是对HSI数据非常重要。
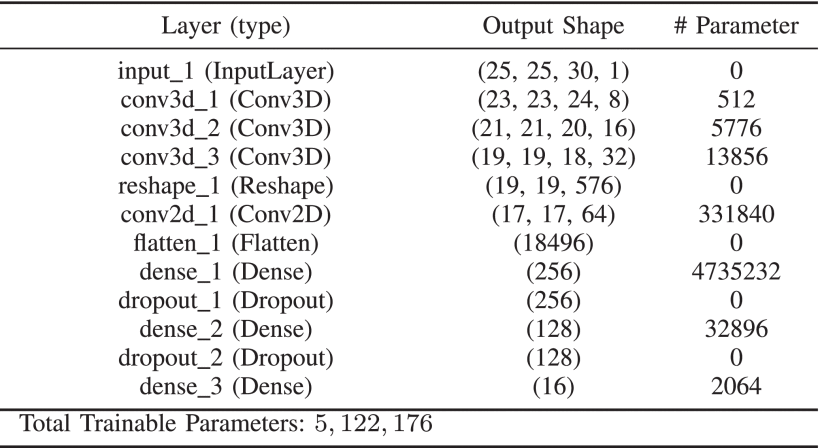
模型的详细参数配置如下表所示,可以看出,第一个FC层(即dense1)参数量最多,最后一个全连接层(dense3)的输出为16,这是因为Indian Pines (IP)数据集的类别数为16。HybridSN中可训练的权重参数总数为5122176,所有参数都是随机初始化的,使用Adam优化器,交叉熵损失函数,学习率为0.001,batch大小为128,训练100个epoch。
下面是我实现的HybridSN模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| class_num = 16
class HybridSN(nn.Module):
def __init__(self, in_channels=1, out_channels=class_num):
super(HybridSN, self).__init__()
self.conv3d_features = nn.Sequential(
nn.Conv3d(in_channels,out_channels=8,kernel_size=(7,3,3)),
nn.ReLU(),
nn.Conv3d(in_channels=8,out_channels=16,kernel_size=(5,3,3)),
nn.ReLU(),
nn.Conv3d(in_channels=16,out_channels=32,kernel_size=(3,3,3)),
nn.ReLU()
)
self.conv2d_features = nn.Sequential(
nn.Conv2d(in_channels=32 * 18, out_channels=64, kernel_size=(3,3)),
nn.ReLU()
)
self.classifier = nn.Sequential(
nn.Linear(64 * 17 * 17, 256),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(128, 16)
)
def forward(self, x):
x = self.conv3d_features(x)
x = x.view(x.size()[0],x.size()[1]*x.size()[2],x.size()[3],x.size()[4])
x = self.conv2d_features(x)
x = x.view(x.size()[0],-1)
x = self.classifier(x)
return x
|
带有Batch Normalization的HybridSN模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| class HybridSN_BN(nn.Module):
def __init__(self, in_channels=1, out_channels=class_num):
super(HybridSN_BN, self).__init__()
self.conv3d_features = nn.Sequential(
nn.Conv3d(in_channels,out_channels=8,kernel_size=(7,3,3)),
nn.BatchNorm3d(8),
nn.ReLU(),
nn.Conv3d(in_channels=8,out_channels=16,kernel_size=(5,3,3)),
nn.BatchNorm3d(16),
nn.ReLU(),
nn.Conv3d(in_channels=16,out_channels=32,kernel_size=(3,3,3)),
nn.BatchNorm3d(32),
nn.ReLU()
)
self.conv2d_features = nn.Sequential(
nn.Conv2d(in_channels=32 * 18, out_channels=64, kernel_size=(3,3)),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.classifier = nn.Sequential(
nn.Linear(64 * 17 * 17, 256),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(128, 16)
)
def forward(self, x):
x = self.conv3d_features(x)
x = x.view(x.size()[0],x.size()[1]*x.size()[2],x.size()[3],x.size()[4])
x = self.conv2d_features(x)
x = x.view(x.size()[0],-1)
x = self.classifier(x)
return x
|
上面我实现了两种模型,一种是原始的HybridSN模型,另一种是带有Batch Normalization的HybridSN模型,下面还会再实现另外两种模型。
四、注意力机制
为了提升HSI分类模型的性能,我也实现了带有注意力机制的HybridSN模型进行训练,这里我采用CBAM: Convolutional Block Attention Module的空间注意力和通道注意力机制。
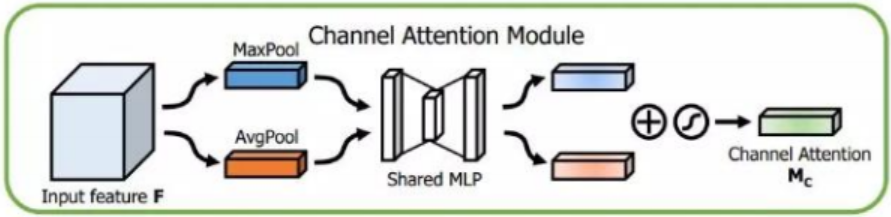
(1)Channnel attetion module(通道注意力模块)
通道注意力模是解决look what的问题,主要是探索不同通道之间特征图的关系,通过分配各个卷积通道上的资源,使模型更应该注意哪一部分特征。通道注意力的过程如下:
- 首先使用MaxPool和AvgPool聚合两个空间维度上的特征,实现时可以用
AdaptiveAvgPool2d和AdaptiveMaxPool2d保证尺寸不变
- 然后通过共享的MLP层,即FC+Relu+FC层,学习每个通道的权重,再将两个特征图相加,后接一个sigmoid函数。
- 最后将结果与未经channel attention的原始输入相乘,从而得到的新的特征图。
Channnel attetion module实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
|
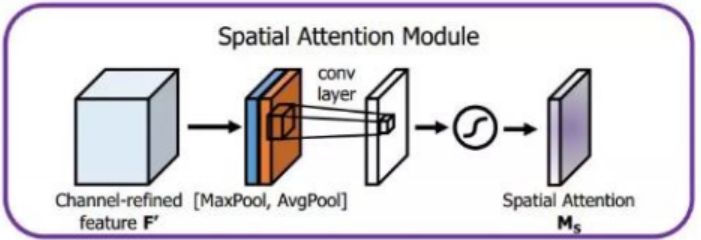
(2)Spatial attention module(空间注意力模块)
空间注意力模块解决的是look where的问题,通过对特征图每个位置进行二维调整(即attention调整),使模型关注到值得更多关注的区域上。空间注意力的过程如下:
- 首先对不同特征图上相同位置的像素值进行全局的MaxPooling和AvgPooling操作,分别得到两个spatial attention map。
- 将这两个特征图concatenate,通过7*7的卷积核对这个feature map进行卷积操作,后接一个sigmoid函数。
- 最后把得到的空间注意力特征图与未经Spatial attention的原始输入相乘,得到的新的特征图。
Spatial attention module实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
|
加上注意力机制的HybridSN模型如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| class_num = 16
class HybridSN_Attention(nn.Module):
def __init__(self, in_channels=1, out_channels=class_num):
super(HybridSN_Attention, self).__init__()
self.conv3d_features = nn.Sequential(
nn.Conv3d(in_channels,out_channels=8,kernel_size=(7,3,3)),
nn.ReLU(),
nn.Conv3d(in_channels=8,out_channels=16,kernel_size=(5,3,3)),
nn.ReLU(),
nn.Conv3d(in_channels=16,out_channels=32,kernel_size=(3,3,3)),
nn.ReLU()
)
self.ca = ChannelAttention(32 * 18)
self.sa = SpatialAttention()
self.conv2d_features = nn.Sequential(
nn.Conv2d(in_channels=32 * 18, out_channels=64, kernel_size=(3,3)),
nn.ReLU()
)
self.classifier = nn.Sequential(
nn.Linear(64 * 17 * 17, 256),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(128, 16)
)
def forward(self, x):
x = self.conv3d_features(x)
x = x.view(x.size()[0],x.size()[1]*x.size()[2],x.size()[3],x.size()[4])
x = self.ca(x) * x
x = self.sa(x) * x
x = self.conv2d_features(x)
x = x.view(x.size()[0],-1)
x = self.classifier(x)
return x
|
加上Batch Normalization、注意力机制的HybridSN模型如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| class HybridSN_BN_Attention(nn.Module):
def __init__(self, in_channels=1, out_channels=class_num):
super(HybridSN_BN_Attention, self).__init__()
self.conv3d_features = nn.Sequential(
nn.Conv3d(in_channels,out_channels=8,kernel_size=(7,3,3)),
nn.BatchNorm3d(8),
nn.ReLU(),
nn.Conv3d(in_channels=8,out_channels=16,kernel_size=(5,3,3)),
nn.BatchNorm3d(16),
nn.ReLU(),
nn.Conv3d(in_channels=16,out_channels=32,kernel_size=(3,3,3)),
nn.BatchNorm3d(32),
nn.ReLU()
)
self.ca = ChannelAttention(32 * 18)
self.sa = SpatialAttention()
self.conv2d_features = nn.Sequential(
nn.Conv2d(in_channels=32 * 18, out_channels=64, kernel_size=(3,3)),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.classifier = nn.Sequential(
nn.Linear(64 * 17 * 17, 256),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(128, 16)
)
def forward(self, x):
x = self.conv3d_features(x)
x = x.view(x.size()[0],x.size()[1]*x.size()[2],x.size()[3],x.size()[4])
x = self.ca(x) * x
x = self.sa(x) * x
x = self.conv2d_features(x)
x = x.view(x.size()[0],-1)
x = self.classifier(x)
return x
|
五、开始实验
上面,我共实现了四种HybridSN模型,分别是:
- 原始的HybridSN模型
- 加上Batch Normalization的HybridSN模型:HybridSN_BN
- 加上通道和空间注意力机制的HybridSN模型:HybridSN_Attention
- 加上Batch Normalization、通道和空间注意力机制的HybridSN模型:HybridSN_BN_Attention
下面我将分别用这四种模型测试Indian Pines数据集,并分析结果。(考虑到篇幅,下面我只写出了主要的方法,全部实现过程请看我的colab)
5.1 下载数据集
Indian Pines 是最早的用于HSI分类的数据集,该数据集有尺寸为145×145 的空间图像和224个波长范围为400~2500nm的光谱反射谱带,由于第 104~108、150-163 和第 220 个波段不能被水反射,因此一般使用的是剔除了这 20 个波段后剩下的 200 个波段作为测试的对象。该数据集共有16类庄稼,用不同的颜色标出。可通过如下方式下载数据集:
1
2
3
| ! wget http://www.ehu.eus/ccwintco/uploads/6/67/Indian_pines_corrected.mat
! wget http://www.ehu.eus/ccwintco/uploads/c/c4/Indian_pines_gt.mat
! pip install spectral
|
5.2 PCA降维
可以把HSI数据立方体表示为I ∈RM×N×D ,其中I为原始输入,M为宽度,N为高度,D为光谱带数(即深度)。I中的每一个HSI像素都包含D个光谱量,并形成一个one-hot 标签向量,Y=(y1,y2,⋯,yC)∈R1×1×C,其中,C表示谱带覆盖类别(land-cover categories)。然而,高光谱像素谱带覆盖类别的混合特性,使得类内差异性和类间相似性较高,这对任何模型来说都具有很大的挑战,为了消除光谱冗余,我们采用主成分分析(PCA)的方法将谱带的数量从D减少到B,同时保持相同的空间尺寸(即宽度M和高度N)。因为只减少了光谱带的数量,从而保留了空间信息,这对识别任何物体都是非常重要的。这里将PCA降维后的数据表示为X∈RM×N×B, 其中X为PCA后的修正输入,M为宽度,N为高度,B为PCA后的谱带数。
为了更好的进行HSI分类,下面将HSI数据立方体划分为一个个小的有重叠的3D-patch,其真值由中心像素的标签决定。对于上面X中的3D neighboring patches P∈RS×S×B ,其空间位置的中心为(α,β),覆盖S×S窗口或空间范围和所有B谱段。因此,在位置(α,β)处的3D-patch,用Pα,β表示,涵盖了宽度从α−(S−1)/2 到 α+(S−1)/2 ,高度从β−(S−1)/2 到 β+(S−1)/2,以及PCA降维后的数据立方体X的所有B谱段。
下面是PCA降维及3D-patch的实现过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
def applyPCA(X, numComponents):
newX = np.reshape(X, (-1, X.shape[2]))
pca = PCA(n_components=numComponents, whiten=True)
newX = pca.fit_transform(newX)
newX = np.reshape(newX, (X.shape[0], X.shape[1], numComponents))
return newX
def padWithZeros(X, margin=2):
newX = np.zeros((X.shape[0] + 2 * margin, X.shape[1] + 2* margin, X.shape[2]))
x_offset = margin
y_offset = margin
newX[x_offset:X.shape[0] + x_offset, y_offset:X.shape[1] + y_offset, :] = X
return newX
def createImageCubes(X, y, windowSize=5, removeZeroLabels = True):
margin = int((windowSize - 1) / 2)
zeroPaddedX = padWithZeros(X, margin=margin)
patchesData = np.zeros((X.shape[0] * X.shape[1], windowSize, windowSize, X.shape[2]))
patchesLabels = np.zeros((X.shape[0] * X.shape[1]))
patchIndex = 0
for r in range(margin, zeroPaddedX.shape[0] - margin):
for c in range(margin, zeroPaddedX.shape[1] - margin):
patch = zeroPaddedX[r - margin:r + margin + 1, c - margin:c + margin + 1]
patchesData[patchIndex, :, :, :] = patch
patchesLabels[patchIndex] = y[r-margin, c-margin]
patchIndex = patchIndex + 1
if removeZeroLabels:
patchesData = patchesData[patchesLabels>0,:,:,:]
patchesLabels = patchesLabels[patchesLabels>0]
patchesLabels -= 1
return patchesData, patchesLabels
def splitTrainTestSet(X, y, testRatio, randomState=345):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=testRatio, random_state=randomState, stratify=y)
return X_train, X_test, y_train, y_test
|
然后,创建数据集加载类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| """ Training dataset"""
class TrainDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtrain.shape[0]
self.x_data = torch.FloatTensor(Xtrain)
self.y_data = torch.LongTensor(ytrain)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
""" Testing dataset"""
class TestDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtest.shape[0]
self.x_data = torch.FloatTensor(Xtest)
self.y_data = torch.LongTensor(ytest)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
|
5.3 训练模型
为了更高效的分析训练结果,我创建了一个训练和测试的方法,然后将上面提到的四种模型作为参数进行训练。
(1)训练方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| def train(net):
current_loss_his = []
current_Acc_his = []
best_net_wts = copy.deepcopy(net.state_dict())
best_acc = 0.0
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
total_loss = 0
for epoch in range(100):
net.train()
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
net.eval()
current_acc = test_acc(net)
current_Acc_his.append(current_acc)
if current_acc > best_acc:
best_acc = current_acc
best_net_wts = copy.deepcopy(net.state_dict())
print('[Epoch: %d] [loss avg: %.4f] [current loss: %.4f] [current acc: %.4f]' %(epoch + 1, total_loss/(epoch+1), loss.item(), current_acc))
current_loss_his.append(loss.item())
print('Finished Training')
print("Best Acc:%.4f" %(best_acc))
net.load_state_dict(best_net_wts)
return net,current_loss_his,current_Acc_his
|
(2)测试方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def test_acc(net):
count = 0
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred_test = outputs
count = 1
else:
y_pred_test = np.concatenate( (y_pred_test, outputs) )
classification = classification_report(ytest, y_pred_test, digits=4)
index_acc = classification.find('weighted avg')
accuracy = classification[index_acc+17:index_acc+23]
return float(accuracy)
|
5.4 可视化结果
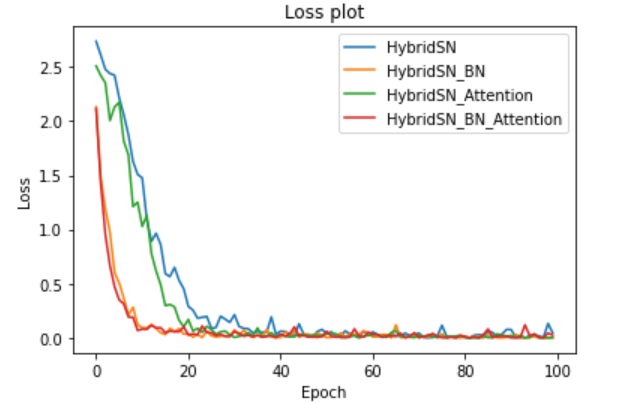
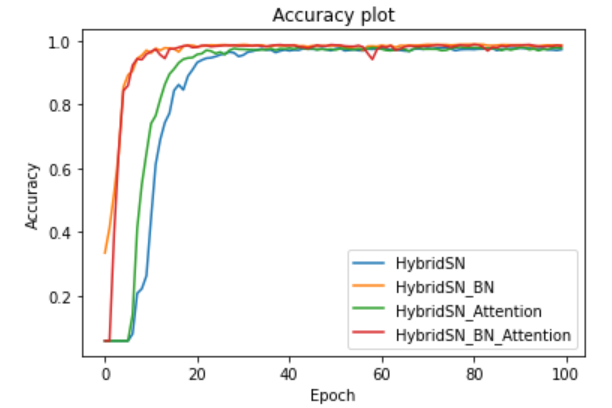
HybridSN、HybridSN_BN、HybridSN_Attention、HybridSN_BN_Attention的训练结果如下:
(1)四种模型的Loss下降曲线
(2)四种模型的Accuracy变化曲线
(3)四种模型最佳Precision、Recall、F1-Score
| 模型 |
Accuracy |
Recall |
F1-Score |
| HybridSN |
0.9790 |
0.9788 |
0.9786 |
| HybridSN_BN |
0.9897 |
0.9888 |
0.9888 |
| HybridSN_Attention |
0.9807 |
0.9806 |
0.9805 |
| HybridSN_BN_Attention |
0.9885 |
0.9884 |
0.9884 |
5.5 分析结论
从收敛速度上看,HybridSN_BN和HybridSN_BN_Attention远快于另外两种模型,说明加上Batch Normalization之后,模型的收敛速度大大提升,而HybridSN_BN和HybridSN_BN_Attention的收敛速度几乎一致,说明Attention并没有提升收敛速度的作用。四种模型大约在25个epoch以后就不怎么收敛了,说明HybridSN本身的收敛速度还是很快的,只不过加了BN以后这种效果更明显了。
从准确度上看,HybridSN_BN、HybridSN_Attention、HybridSN_BN_Attention均高于HybridSN,说明Attention和Batch Normalization都有提升模型分类准确度的作用,相比HybridSN_Attention而言,HybridSN_BN提升的效果更明显,这就说明了BN不仅提升收敛速度方面效果显著,在提升准确度方面也是很不错的。但是,HybridSN_BN_Attention相比HybridSN_BN,无论是Precision、Recall还是F1-Score,都下降了,说明了BN和Attention这两种机制并不搭配,在下面的思考中,我也给出了为什么会出现这种情况个人理解。
可以看到,HybridSN模型的收敛速度很快,能在25个epoch内实现,准确度也很高,四种模型的准确度都达到了97%以上,说明采用三维和二维卷积的混合网络,是非常有助于解决高光谱图像分类问题的。
六、思考
(1)二维卷积和三维卷积的区别
二维卷积是最常见、用途最广泛的卷积,主要用于提取空间特征,对于一张图片来说,可以根据设定的卷积核的不同,提取不同的特征,如数字图像处理中模糊、锐化、去噪操作都是用特定卷积核实现的。在CNN中,二维卷积的卷积核权重是可学习的,再加上激活函数的非线性变换,几乎可以拟合出任何想要的模型。三维卷积的卷积核可以看作一个数据立方体,因此三维卷积处理的对象是一个立方体图像(或其它相似的数据),三维卷积的思想与二维卷积相同,只不过多了一个维度,所以三维卷积不仅提取处理空间特征,也可以提取除了空间特征以外的另一维度的特征。由于高光谱图像不仅有空间信息,还有不同波长的光谱信息,因此使用三维卷积来提取高光谱图像的特征就再好不过了,但是三维卷积有一个致命的缺点,就是计算复杂度太高,参数量也比二维卷积多出了一维维度的倍数,所以采用三维和二维卷积的混合网络即降低了模型的复杂性,也提升了模型的性能。
(2)为什么Batch Normalization能够加快收敛速度
Batch Normalization,顾名思义,以进行学习时的batch为单位,按batch进行规范化。具体而言,把每层神经网络任意神经元输入值的分布强行拉回到均值为0方差为1的标准正态分布,用数学式表示的话,如下所示:
m代表batch的大小,μB为批处理数据的均值,σB2为批处理数据的方差。
BN层可以让激活函数(非线性变化函数)的输入数据落入比较敏感的区域,缓解了梯度消失问题,加速了网络收敛速度。同时,BN层将每一个batch的均值与方差引入到网络中,由于每个batch的这两个值都不相同,可看做为训练过程增加了随机噪音,可以起到一定的正则效果,防止过拟合。
(3)为什么多测试几次网络会发现每次分类的结果都不一样?
我认为导致网络每次测试的结果都不一样原因是:没有使用net.eval()将模型切换至测试模式。我们知道,dropout的本质通过在学习过程中随机删除神经元,从而每一次都让不同的模型进行学习。比如,以概率 p=0.6 随机将神经元置0,就相当于在10个神经元选4个神经元输出(4个神经元在工作,另外6神经元置0),这时我们就相当于训练了 C104 个模型,只是每个模型的参数量更少了。如果测试时仍处理训练模式,那么也会随机将神经元置为0,这就带来了不确定的结果,而在测试模式下,dropout层会让所有的激活单元都通过,最后的输出再乘以 (1-p) 作为模型的测试结果,这样得到的数据就是确定的了。同样的,是否处于测试模式也会影响BN层的工作机制,从而影响测试的结果。因此,合理的运用model.train()和model.eval()对测试的结果是至关重要的。
(4)如果想要进一步提升高光谱图像的分类性能,可以如何使用注意力机制?
在上述实验中,给HybridSN加上注意力机制后模型的性能有了提升,我也尝试了把注意力机制加在HybridSN模型不同位置上作比较(结果没有在上面呈现),发现把Attention加在第三个三维卷积后,二维卷积之前比加在二维卷积后效果更好。我认为这是因为高光谱图像经过二维卷积之后会损失一部分光谱信息,如果将注意力机制加在二维卷积之后,那么Attention抽取关键信息的效果就不明显了(会忽略少部分光谱信息的关键区域),所以应该把Attention加在第三个三维卷积后,这样会保留更多的光谱信息,从而进一步提升高光谱图像的分类性能。从上面的结果中也看到了,加上Attention之后,模型的Precision、Recall、F1-Score都提升了。
(5)为什么HybridSN_BN_Attention的性能不如HybridSN_BN?
我刚开始也很疑惑,为什么两个被公认性能优越的模块加在一起后性能反而下降了呢?我想了很久,得出了自己的一点理解:因为BN是固定每一次输入Batch的分布,把每层神经网络任意神经元输入值的分布强行拉回到均值为0方差为1的标准正态分布,而Attention是为了获取更加显著的区域,经过Attention后显著的区域会变得更为突出,这在一定程度上打乱了原来输入的分布,从这方面来讲,这两个模块似乎是一种相互互斥的存在,效果自然就下降了。这相当于一个精通python的人认为python是世界上最好的语言,而另一个精通java的人认为java是最好世界上的语言,当一个人即会java也会python时,它可能任何一个都不精通。当然,得到这样的结果也可能是如下原因造成:
- 由于Indian Pines数据集自身特点,模型对其分类性能的评估并没有广义性,可能在另外一个数据集上BN+Attenion的性能又比只有BN的模型好了
- 模型本身的结果可能就存在问题,如果调整一下各个模块的顺序,改变各个模块内卷积核的参数,结果会不会更好呢?
由于时间原因及个人知识水平的限制,并没有做更多的探索,还望见谅。
七、结语
HybridSN是一种用于HSI分类的混合网络模型,以三维和二维卷积结合的方式既提升了模型的性能,也降低了复杂度。另外,分别加上BN、Attention之后,模型的性能都有了提升,BN提升更加明显,但是把BN和Attention一起加在HybridSN中,会发现HybridSN_BN_Attention的性能虽然比原始的HybridSN有所提升,但不如HybridSN_BN,我认为这是因为两个模块是一种互斥的存在,从而导致HybridSN_BN的性能降低,上面也给出了自己的解释。这次实验让我学到了很多,不仅熟练掌握了HSI分类,也对BN和Attention的印象更加深刻,更明白了不是所有优秀的模块组合起来就能取得好的结果,只有不断的分析、实践、思考,才能更好的理解其本质。
最后,附上本文在colab的实现过程:https://colab.research.google.com/drive/12QbZqcxfplFEm7yp3X9wgi7jYXmqRjz9?usp=sharing
【参考文档】
HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification
CBAM: Convolutional Block Attention Module
高光谱数据集
高光谱图像