机器学习概述
在这里将学到:
- 什么是机器学习
- 为什么需要机器学习
- 机器学习中的基本概念:包括样本、特征、标签、模型、学习算法
- 机器学习的三要素:模型、评价准则、优化算法
- 训练集、测试集、样本集的概念
什么是机器学习
通俗地讲, 机器学习 (Machine Learning, ML)让计算机从数据中进行自动学习,得到某种知识,而不是人为指定且明显的去编程。以手写体数字识别为例,我们需要让计算机能自动识别手写的数字,由于每个人的写法都不相同,我们很难总结每个数字的手写体特征,因此设计一套识别算法几乎是一项几乎不可能的任务。

在现实生活中,很多问题都类似于手写体数字识别这类问题,比如物体识别、语音识别等。对于这类问题,我们不知道如何设计一个计算机程序来解决。因此,人们开始尝试采用另一种思路,即让计算机“看”大量的样本,并从中学习到一些经验,然后用这些经验来识别新的样本。要识别手写体数字,首先通过人工标注大量的手写体数字图像(即每张图像都通过人工标记了它是什么数字),这些图像作为训练数据,然后通过学习算法自动生成模型,并依靠它来识别新的手写体数字。这和人类学习过程也比较类似,我们教小孩子识别数字也是这样的过程。这种通过数据来学习的方法就称为机器学习的方法。
机器学习自动生成的模型也称为决策函数

机器学习的基本概念
机器学习中的一些基本概念:包括样本、特征、标签、模型、学习算法等。以一个生活中的经验学习为例,假设我们要到市场上购买芒果,但是之前毫无挑选芒果的经验,那么我们如何通过学习来获取这些知识?

首先,我们从市场上随机选取一些芒果,列出每个芒果的特征 (Feature),包括颜色,大小,形状,产地,品牌,以及我们需要预测的标签 (Label)。标签可以是连续值(比如关于芒果的甜度、水分以及成熟度的综合打分),也可以是离散值(比如好、坏两类标签)。
一个标记好特征以及标签的芒果可以看作是一个样本 (Sample)。一组样本构成的集合称为数据集 (Data Set)。一般将数据集分为两部分:训练集和测试集。 训练集 (Training Set)中的样本是用来训练模型的,也叫训练样本(Training Sample),而测试集 (Test Set)中的样本是用来检验模型好坏的,也叫测试样本(Test Sample)。
特征也可以称为属性(Attribute),样本(Sample),也叫示例(Instance)。
我们用一个 d 维向量 表示一个芒果的所有特征构成的向量,称为特征向量 (Feature Vector),其中每一维表示一个特征。
假设训练集由 N 个样本组成,其中每个样本都是独立同分布 (Identically and Independently Distributed, IID)的,即独立地从相同的数据分布中抽取的,记为
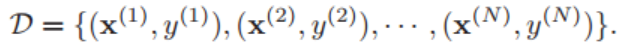
其中,表示第一个样本的特征向量,第一个样本的标签
给定训练集 ,我们希望让计算机自动寻找一个函数 来建立每个样本特性向量 X 和标签 y 之间的映射。对于一个样本 ,我们可以通过决策函数来预测其标签的值
或标签的条件概率
其中 为可学习的参数
通过一个学习算法 (Learning Algorithm) ,在训练集上找到一组参数 ,使得函数 可以近似真实的映射关系。这个过程称为学习 (Learning)或训练 (Training)过程,函数 称为模型 (Model)。
在有些文献中,学习算法也叫做学习器 (Learner)。
下次从市场上买芒果(测试样本)时,可以根据芒果的特征,使用学习到的模型 来预测芒果的好坏。为了评价的公正性,我们还是独立同分布地抽取一组样本作为测试集 ,并在测试集中所有样本上进行测试,计算预测结果的准确率。
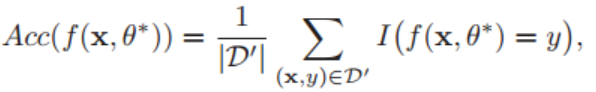
其中 为指示函数, 为测试集大小。(对于分类,一般是求出总测试集样本的个数和预测正确的个数)
下图给出了机器学习的基本概念。对一个预测任务,输入特征向量为 ,输出标签为 ,我们选择一个函数 ,通过学习算法 和一组训练样本 ,找到一组最优的参数 ,得到最终的模型 。这样就可以对新的输入 进行预测。
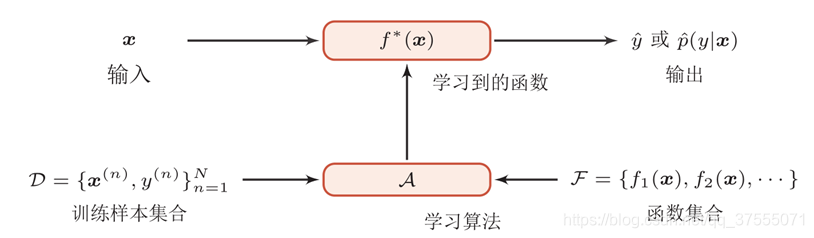
机器学习的三要素
机器学习方法可以分为三个基本要素:模型、学习准则、优化算法。
模型
输入空间默认为样本的特征空间

为实数,为参数的数量,表示有m个实数要学习
线性模型:
线性模型的假设空间为一个参数化的线性函数族,
其中,是特征向量,是权重向量,是偏置
非线性模型:

比如,卷积神经网络中的卷积运算本身就是一个可以学习非线性基函数
学习准则
学习准则就是找到可以评价学习成果好坏的准则,如果用函数表示,则成为损失函数
损失函数是一个非负实数函数,,用 来表示,用来量化模型预测和真实标签之间的差异。
常见回归损失函数有:
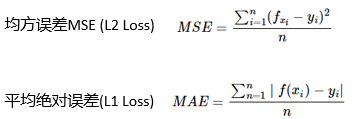
常见分类损失函数有:交叉熵损失函数 (Cross-Entropy Loss Function)
优化算法
梯度下降
关于验证集的一点补充
将数据分为训练集和测试集对于简单的模型和样本来说就够了,但是对于复杂的模型(如CNN)和样本(如图片),就需要将数据集分类三部分:训练集、验证集、测试集
- 训练集(Training Set):用来训练模型的
- 验证集(Validation set):用于对模型的能力进行初步评估,可以作为调参、选择特征等算法相关的选择的依据。
- 测试集 (Test Set):用来评估模最终模型的泛化能力,不能作为调参、选择特征等算法相关的选择的依据
就好比考试一样,我们平时做的题相当于训练集,测试集相当于最终的考试,我们通过最终的考试来检验我们最终的学习能力,将测试集信息泄露出去,相当于学生提前知道了考试题目,那最后再考这些提前知道的考试题目,当然代表不了什么,你在最后的考试中得再高的分数,也不能代表你学习能力强。所以说,如果通过测试集来调节模型,相当于不仅知道了考试的题目,学生还都学会怎么做这些题了(因为我们肯定会人为的让模型在测试集上的误差最小,因为这是你调整超参数的目的),那再拿这些题考试的话,人人都有可能考满分,但是并没有起到检测学生学习能力的作用。原来我们通过测试集来近似泛化误差,也就是通过考试来检验学生的学习能力,但是由于信息泄露,此时的测试集即考试无任何意义,现实中可能学生的能力很差。所以,我们在学习的时候,老师会准备一些小测试来帮助我们查缺补漏,这些小测试也就是要说的验证集。我们通过验证集来作为调整模型的依据,这样不至于将测试集中的信息泄露。
- 训练集-----------学生的课本;学生 根据课本里的内容来掌握知识。
- 验证集------------作业,通过作业可以知道 不同学生学习情况、进步的速度快慢。
- 测试集-----------考试,考的题是平常都没有见过,考察学生举一反三的能力。
也就是说我们将数据划分训练集、验证集和测试集。在训练集上训练模型,在验证集上评估模型,一旦找到的最佳的参数,就在测试集上最后测试一次,测试集上的误差作为泛化误差的近似。关于验证集的划分可以参考测试集的划分,其实都是一样的,这里不再赘述。
总结
- 机器学习让计算机从数据中进行自动学习,得到某种知识,而不是人为指定且明显的去编程
- 之所以机器学习,是因为现实世界的问题都比较复杂,很难通过规则来手工实现
- 机器学习中的基本概念:包括样本、特征、标签、模型、学习算法
- 机器学习的三要素:模型、评价准则、优化算法
- 训练集、测试集、样本集的概念
声明:本文大部分摘录自神邱老师的《神经网络与深度学习》,加上一小部分个人的理解和其他博客的资料,因此将本文声明为转载,本文只做学习和交流使用,如有侵权请联系博主删除。
参考文档
【神经网络与深度学习-邱锡鹏著】
训练集、验证集、测试集以及交验验证的理解
训练集、验证集和测试集