ResNet残差网络及变体详解(符代码实现)
本文通过分析深度网络模型的缺点引出ResNet残差网络,并介绍了几种变体,最后用代码实现ResNet18。
前言
ResNet(Residual Network, ResNet)是微软团队开发的网络,它的特征在于具有比以前的网络更深的结构,在2015年的ILSVRC大赛中获得分类任务的第1名。
网络的深度对于学习表达能力更强的特征至关重要的。网络的层数越多,意味着能够提取的特征越丰富,表示能力就越强。(越深的网络提取的特征越抽象,越具有语义信息,特征的表示能力就越强)。
但是,随着网络深度的增加,所带来的的问题也是显而易见的,主要有以下几个方面:
- 增加深度带来的首个问题就是梯度爆炸/消散的问题,这是由于随着层数的增多,在网络中反向传播的梯度会随着连乘变得不稳定,变得特别大或者特别小。这其中经常出现的是梯度消散的问题。
- 为了克服梯度消散也想出了许多的解决办法,如使用BatchNorm,将激活函数换为ReLu等,但是改善问题的能力有限。
- 增加深度的另一个问题就是网络的degradation(退化)问题,即随着深度的增加,网络的性能会越来越差。如下所示:

为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构——ResNet(Residual Network,残差网络)。通过使用残差网络结构,深层次的卷积神经网络模型不仅避免了出现模型性能退化的问题,并取得了更好的性能。
需要注意的是,Residual Network不是为了解决过拟合的问题,因为过拟合只是在测试集上错误率很高,而在训练集上错误率很低,通过上图可以出,随着深度的加深而引起的 model degradation(模型退化)不仅在训练集上错误率高,在测试集上错误率也很高。所以说 Residual Network 主要是为了解决因网络加深而导致的模型退化问题(也有效避免了梯度消散问题,下面会讲)。
模型退化
通常,当我们堆叠一个模型时,会认为效果会越堆越好。因为,网络的层数越多,意味着能够提取到的特征越丰富,特征的表示能力就越强,假设一个比较浅的网络已经可以达到不错的效果,那么再进行叠加的网络如果什么也不做,效果不会变差。
事实上,这是问题所在,因为“什么都不做”是之前神经网络最难做到的事情之一。这时因为由于非线性激活函数(Relu)的存在,每次输入到输出的过程都几乎是不可逆的(信息损失),所以很难从输出反推回完整的输入。所以随着深度的加深而引起的 model degradation(模型退化)仅通过普通网络模型是无法避免的。
Residual Learning(残差学习)设计的本质,是让模型的内部结构具有恒等映射的能力,至少让深度网络实现和浅层网络一样的性能,即让深度网络后面的层至少实现恒等映射的作用,这样在堆叠网络的过程中,不会因为继续堆叠而产生退化。
在mobileNetV2论文中,作者说明了使用ReLU的问题,即当使用ReLU等激活函数时,会导致信息丢失,如下所示:

低维(2维)的信息嵌入到n维的空间中(即Input的特征经过高维空间进行变换),并通过随机矩阵对特征进行变换,之后再加上ReLU激活函数,之后在通过 (T的逆矩阵)进行反变换。当n=2,3时,会导致比较严重的信息丢失,部分特征重叠到一起了;当n=15到30时,信息丢失程度降低。
残差结构

在上图中,我们可以使用一个非线性变化函数来描述一个网络的输入输出,即深层的输入为X(X也为浅层的输出),深层的输出为F(x)+x,F通常包括了卷积,激活等操作。
这里需要注意附加的恒等映射关系具有两种不同的使用情况:残差结构的输入数据若和输出结果的维度一致,则直接相加;若维度不一致,必须对x进行升维操作,让它俩的维度相同时才能计算。升维的方法有两种:
- 直接通过zero padding 来增加维度(channel);
- 用1x1卷积实现,直接改变1x1卷积的filters数目,这种会增加参数。
令H(x)=F(x)+x,即H(x)为深层的输出,则 F(x)=H(x)−x。此时残差结构如下图所示,虚线框中的部分就是F(x),即H(x)−x。

当浅层的x代表的特征已经足够成熟(即浅层网络输出的特征x已经达到了最优),再经过任何深层的变换改变特征x都会让loss变大的话,F(x)会自动趋向于学习成为0,x则从恒等映射的路径继续传递。这样就在不增加计算成本的情况下实现了目的:在前向过程中,当浅层的输出已经足够成熟,让深层网络后面的层能够实现恒等映射的作用(即让后面的层从恒等映射的路径继续传递),这样就解决了由于网络过深而导致的模型退化的问题。
从另一方面讲,残差结构可以让网络反向传播时信号可以更好的地传递,以一个例子来解释。
假设非残差网络输出为G(x),残差网络输出为H(x),其中H=F(x)+x,输入的样本特征 x=1。(注意:这里G和H中的F是一样的,为了区分,用不同的符号)
(1)在某一时刻:
非残差网络G(1)=1.1, 把G简化为线性运算,可以明显看出。
残差网络H(1)=1.1, H(1)=F(1)+1, F(1)=0.1,把F简化为线性运算,。
(2)经过一次反向传播并更新G和F中的与后(输入的样本特征x不变,仍为1):
非残差网络G’(1)=1.2, 此时
残差网络H’(1)=1.2, H’(1)=F’(1)+1, F’(1)=0.2,
可以明显的看出,F的参数就从0.1更新到0.2,而G的参数就从1.1更新到1.2,这一点变化对F的影响远远大于G,说明引入残差后的映射对输出的变化更敏感,对权重的调整作用更大,所以效果更好。
从另外一方面来说,对于残差网络H=F(x)+x,每一个导数就加上了一个恒等项1,dh/dx=d(f+x)/dx=1+df/dx,此时就算原来的导数df/dx很小,这时候误差仍然能够有效的反向传播,有效避免了非残差网络链式求导连乘而引发的梯度消散。
这里可能要有人问,反向传播不应该是对权重求偏导吗,这里怎么是对x求偏导?
反向传播的目的是为了更新权重,但是反向传播的过程是用链式法则实现,在这个过程中,网络中间层的x和w都会参与回传。乘法的反向传播会将上游的值乘以正向传播时的输入信号的“翻转值”后传递给下游,加法节点的反向传播将上游的值原封不动地输出到下游。
因此,从上面的分析可以看出,残差模块最重要的作用就是改变了前向和后向信息传递的方式从而很大程度上促进了网络的优化。
- 前向:当浅层的输出已经足够成熟,让深层网络后面的层能够实现恒等映射的作用(即让后面的层从恒等映射的路径继续传递),解决了由于网络过深而导致的模型退化的问题。
- 后向:引入残差后的映射对输出的变化更敏感,对权重的调整作用更大,效果更好。
至于为何 shortcut(即附加的恒等映射关系)的输入时X,而不是X/2或是其他形式。kaiming大神的另一篇文章 Identity Mappings in Deep Residual Networks 中探讨了这个问题,对以下6种结构的残差结构进行实验比较,shortcut 是X/2的就是第二种,结果发现还是第一种效果好。

ResNet的研究者还提出了能够让网络结构更深的残差模块,如下图所示:
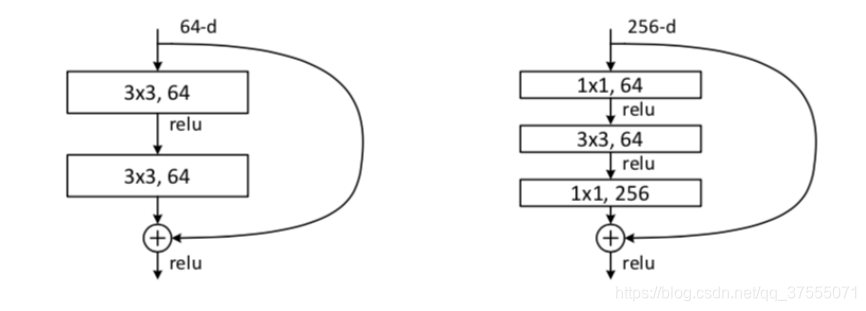
将原来的building block(残差结构)改为bottleneck(瓶颈结构),很好地减少了参数数量,即先用第一个1x1的卷积把256维channel降到64维,第三个1x1卷积又升到256维,总共用参数:1x1x256x64+3x3x64x64+1x1x64x256=69632,如果不使用 bottleneck,参数将是 3x3x256x256x2=1179648,差了16.94倍。
总的来说,由于将原来的building block(残差结构)改为bottleneck(瓶颈结构)减少了模型训练的参数量,同时减少整个模型的计算量,并且网络深度得以增加,这使得拓展更深的模型结构成为可能,于是出现了拥有50层、101层、152层的ResNet模型,这不仅没有出现模型性能退化的问题,而且错误率和计算复杂度都保持在很低的程度。
作者最后在Cifar-10上尝试了1202层的网络,结果在训练误差上与一个较浅的110层的相近,但是测试误差要比110层大1.5%。作者认为是采用了太深的网络,发生了过拟合。所以现在的残差结构最多到100多层,不能再深了,后面会讲到如何把残差网络扩展到1000层。
ResNet网络结构
我们以VGG作对比介绍ResNet网络。看下图:
左边为基本的VGGNet,中间为基于VGG作出的扩增至34层的普通网络,右边为34层的残差网络,不同的是每隔两层就会有一个residual模块。对于残差网络(右图),维度匹配的shortcut连接为实线(输入和输出有相同的通道数),反之为虚线。维度不匹配时,同等映射有两种可选方案:全0填充和1x1卷积。
常用的ResNet有5种常用深度:18,34,50,101,152层。网络分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x。如下图所示:

根据上图,ResNet101的层数为3 + 4 + 23 + 3 = 33个building block,每个block为3层,所以有33 x 3 = 99层,再加上第一层的卷积conv1,以及最后的fc层(用于分类),一共是99+1+1=101层。
以往模型大多在ImageNet上作测试,所以这里只给出在ImageNet上的成绩,如下所示:

可以看到,由于使用1×1的卷积层来减少模型训练的参数量,同时减少整个模型的计算量,增加了网络的深度,152层的ResNet相比于其他网络有提高了一些精度。
Pre Activation ResNet
由于ResNet引入了残差模块,很好的解决了网络模型degradation的问题,从而提高了网络深度。由于将原来的building block(残差结构)改为bottleneck(瓶颈结构)减少了模型训练的参数量,同时减少整个模型的计算量,这使得拓展更深的模型结构成为可能,于是出现了拥有50层、101层、152层的ResNet模型,那么,我们还能不能加深一些呢?100层可以,1000层呢?
答案是不可以,至少目前的残差模型是不行的,因为目前的残差块在加和之后会经过一个relu,由于这个激活函数Relu的位置带来的影响,使得增加的操作虽然在100层中不会有很大的影响,但是在1000层的超深网络里面还是会阻碍整个网络的前向反向传播(具体原因接着往下看),我们需要接着改进。
当前卷积神经网络的基本模块通常为卷积+归一化+激活函数(conv+bn+relu)的顺序,对于普通的按照这些模块进行顺序堆叠的网络来说,各个模块的顺序没有什么影响,但是对于残差网络来说却不一样。
pre activation 和 post activation ,也就是激活函数Relu的位置,是放在卷积前还是卷积后。对于一般的网络来说,这是没什么区别的,因为网络是各个模块进行叠加,这个卷积块的激活函数的输出就是另一卷积块的激活函数的输入,总体来看无所谓先后。
但是,残差网络不一样,它的残差分支包含着完整的卷积,归一化,激活函数层,而后这一分支要和原始信号分支进行相加,因此就有了多种方案,如下图所示:

我们最常见的是图a的形式,即原始信号和残差信号相加之和再经过Relu输出到下一个block,但实际上还有b、c、d、e等形式,它们的性能如下:

图b,将BN拿出来,放到加和函数之后,结果最差,分析原因可能是不应该把原始信号和残差信号一起加和后归一化,改变了原始信号的分布。
图c,将ReLU提到残差分支,结果也不行,因为这样一来,残差分支的信号就是非负的,当然会影响表达能力,结果也就变得更差了。
图a是原始的ResNet模块,我们可以看到原始信号和残差信号相加后需要进入Relu做一个非线性激活,这样一来,相加后的结果永远是非负的,这就约束了模型的表达能力(和图c原理类似),因此需要做一个调整。图d和图e都是讲ReLU提到了卷积之前,但是BN的顺序有所不同。图d在临近输出放了BN,然后再和原始信号相加,本来BN就是为了给数据一个固定的分布,一旦经过别的操作就会改变数据的分布,会削减BN的作用,在原版本的resnet中就是这么使用的BN,所以,图d效果与原始的ResNet(图a)性能大致相当。图e在临近输入放了BN,效果大大提升,这应该是来自于BN层的功劳,本来BN层就应该放置在卷积层之前提升网络泛化能力。
我们来看下这两种结构在CIFAR-10和CIFAR-100上的效果吧:

原始的ResNet结构增加到1000层错误率反而提高,但是用上Pre Activation unit后把网络增加到1000层,错误率显著降低,值的注意的是这里所有精度提升都是出自于深度的增加。
1000层的残差网络和100层的网络之间的计算复杂度基本是线性的,因此从时间和算力的角度而言还是100层的网络更加实用,但是改进后的残差模块证明了1000层的网络的可实现性,实际上现在各大厂每次开会都要拿超深的网络出来吓人,原理就是这个模块。
那么,我们有没有什么其他不是靠深度的办法来增加特征的表征能力呢?如果有的话结合上ResNet的深度,会不会产生很好的效果呢?
其它的ResNet变体
Wide ResNet
Wide ResNet,就是比普通的残差网络更宽(也就是通道数量更大)的结构,那么它与ResNet有什么不同呢?
首先,看一下几个不同的残差模块的对比,如下所示:

(a)是普通的残差结构,(b)是使用1*1卷积进行升维和降维的结构,© 是直接增加网络的宽度,图中方块的宽度就表示它的残差块的通道数更大。(d)是文章中提出,可以看到相比于基础模块在中间加上了dropout层,这是因为增加了宽度后参数的数量会显著增加,为了防止过拟合使用了卷积层中的dropout,并取得了相比于不用dropout更好的效果。
作者们实验结果表明:16层的改进残差网络就达到了1000层残差网络的性能,而且计算代价更低。
Wide ResNet网络结构如下所示:

作者通过实验发现每个残差内部由两个3*3卷积层组成可以有最好的效果,上图是改进后模型的基本架构,与ResNet唯一不同的是多了一个k,代表了原始模块中卷积核数量的k倍(也就是通道数量更大),B(3,3) 代表每一个残差模块内由两个3*3的卷积层组成。

上图是164层原始残差网络和28层十倍宽度残差网络在CIFAR-10和CIFAR-100数据集上的比较,实线是在测试集上的错误率,虚线是在训练集上的错误率,可以看到,改进后的宽网络无论在测试集上还是在训练集上都有更低的错误率。
下图是不同宽度的模型之间纵向比较,同深度下,随着宽度增加,准确率增加。深度为22层,宽度为原始8倍的模型比深度为40层的同宽的模型准确率还要高

我们可以得到如下结论:
- 在同深度情况下,增大宽度可以增加各种深度的残差模型的性能
- 宽度和深度的增加就可以使性能提升。
- 深度的增加对于模型的提升是有限的,在一定范围内,增加深度可以使模型性能提升,但是一定程度以后,在增加模型的深度,反而有更高的错误率
- 从某种意义上来说,宽度比深度增加对于模型的提升更重要。
Inception v4
这里推荐看一下我的博客深入解读GoogLeNet网络结构,可以更好的理解Inception模块。作者在Inceptionv4论文中共提出了3个新的网络:Inceptionv4、Inception-ResNetv1、Inception-ResNetv2,并拿这三个网络加上Inceptionv3一起进行比较。
作者认为,对于训练非常深的卷积模型,残差连接本质上是必需的。但似乎发现并不支持这种观点,至少对于图像识别来说是的。但是,它可能需要更多的测试数据和更深的模型来了解残差连接提供的有益方面的真实程度。在实验部分,作者证明了在不利用残差连接的情况下训练非常深的网络并不是很困难。然而,使用残差连接似乎大大提高了训练速度,这仅仅是它们使用的一个很好的论据。也就是说Residual connection并不是必要条件,只是使用了Residual connection会加快训练速度。
我们直接来看Inception-ResNet的网络结构吧(下图)。值得注意的是,Inception-ResNetv1计算代价跟Inception-v3大致相同,Inception-ResNetv2的计算代价跟Inception-v4网络基本相同。

这里其他模块不介绍了,现在只重点关注Inception的ResNet模块部分。
Inception-ResNet-v1和Inception-ResNet-v2对应的Inception-resnet-A模块为:
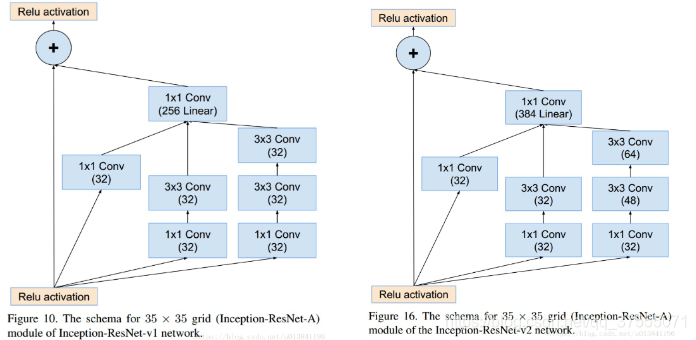
如上面的图片所示,改进主要有两点。1. 将residual模块加入inception,2. 将各分支的输出通过聚合后通过同一个1*1的卷积层来进行通道的扩增。
Inceptionv4比Inceptionv3层次更深、结构更复杂,并且IncpetionV4对于Inception块的每个网格大小进行了统一。Inception-ResNet在Inception块上加了残差连接加快训练速度。Inception-ResNet-v2的整体框架和Inception-ResNet-v1是一致的,只不过v2的计算量更加expensive些(输出的channel数量更多)。它们训练精度如下:

从上图可以看出,加了Residual模块的模型训练速度明显比正常的Inception模型快一些,而且也有稍微高一些的准确率。最后,Inception-ResNet-v2的Top-5准确率达到了3.1%,如下图所示:

想要更详细的了解Inceptionv4,可以参考这两篇博客Inceptionv4论文详解 和 卷积神经网络的网络结构——Inception V4
ResNext
ResNeXt基于wide residual和inception,提出了将残差模块中的所有通道分组进行汇合操作会有更好的效果。同时也给inception提出了一个简化的表示方式。
简化的inception如下所示:

与原始的Inception相比,简化的Inception将不同尺寸的卷积核和池化等归一化为3*3的卷积核,并且每个分支都用 1*1 的卷积核去扩展通道后相加就得到了上面的结构,再这个基础上加上shortcut就得到了ResNext模块:

ResNext包含了32个分支的基模块,每个分支一模一样。每一个框中的参数分别表示输入维度,卷积核大小,输出维度,如256,1x1,64表示当前网络层的输入为256个通道,使用1x1的卷积,输出为64个通道。ResNext通过1x1的网络层,控制通道数先进行降维,再进行升维,然后保证和ResNet模块一样,输入输出的通道数都是256。因此,可以总结如下:
- 相对于Inception-Resnet,ResNext的每个分支都是相同的结构,相对于Inception,网络架构更加简洁。
- Inception-Resnet中的先各分支输出并concat,然后用1 * 1卷积变换深度的方式被先变换通道数后单位加的形式替代。
- 因为每个分支的相同结构,可以提出除了深度和宽度之外的第三维度cardinality,即分支的数量。
ResNext结构对比普通的ResNet结构,如下所示:

从另外一个角度,ResNext是也可以看做一个增加了分组的残差模块,对于上图的ResNet结构的第一个卷积模块,输入为256维,输出为64维。右侧包含了32个同样的支路,每一个支路的输入为256维,输出为4维。不过两者的参数量是相当的,如下所示:

类比Wide Residual的配置图,二者一个是改变了卷积核的倍数,一个增加了分组,但都是在残差模块做工作。 不同深度、不同宽度、不同分组的网络对比如下:

可以看到,相对于100层的残差网络,用深度,宽度,和cardinality三种方式增大了两倍的复杂度,相同复杂度下,分组更多即C更大的模型性能更好,这说明cardinality是一个比深度和宽度更加有效的维度。而且,ResNext的计算速度更快,因为ResNext的结构本来就非常适合硬件并行处理。
ResNet18的实现
残差块的实现如下。它可以设定输出通道数、是否使用额外的 1×1 卷积层来修改通道数以及卷积层的步幅。
1 | import time |
下面我们来查看输入和输出形状一致的情况:
1 | blk = Residual(3, 3) |
我们也可以在增加输出通道数的同时减半输出的高和宽。
1 | X = torch.rand((4, 3, 6, 6)) |
ResNet的前两层跟之前介绍的GoogLeNet中的一样:在输出通道数为64、步幅为2的7×7卷积层后接步幅为2的3×3的最大池化层。不同之处在于ResNet每个卷积层后增加的批量归一化层。
1 | resnet_18 = nn.Sequential( |
GoogLeNet在后面接了4个由Inception块组成的模块。ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为2的最大池化层,所以无须减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
下面我们来实现这个模块。注意,这里对第一个模块做了特别处理。
1 | def resnet_block(in_channels, out_channels, num_residuals, first_block=False): |
接着我们为ResNet加入所有残差块。这里每个模块使用两个残差块。
1 | resnet_18.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True)) |
最后,与GoogLeNet一样,加入全局平均池化层后接上全连接层输出。
1 | class GlobalAvgPool2d(nn.Module): |
这里每个模块里有4个卷积层(不计算1×1卷积层),加上最开始的卷积层和最后的全连接层,共计18层。这个模型通常也被称为ResNet-18。通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。虽然ResNet的主体架构跟GoogLeNet的类似,但ResNet结构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。
我们来观察一下输入形状在ResNet不同模块之间的变化。
1 | X = torch.rand((1, 1, 224, 224)) |
另外,本文用到的论文我上传到百度云上了,有需要的请自提,链接:https://pan.baidu.com/s/1cParM5EEOz3QOQgjAZt9jA 提取码:ngvb 。包含如下三个论文:
- Identity Mappings in Deep Residual Networks
- Wide Residual Networks
- AggregatedResidualTransformationsforDeepNeuralNetworks
【参考文档】
深度学习网络篇——ResNet
resnet中的残差连接,你确定真的看懂了?
残差网络(ResNet)
残差网络ResNet笔记
CNN 经典网络之-ResNet
深度学习之Pytorch实战计算机视觉-唐进民著