Python中字符串与正则表达式的25个常用操作
Python 中没有像 C++ 表示的字符类型(char),所有的字符或串都被统一为 str 对象。如单个字符 c 的类型也为 str,因此在python中字符也就是字符串
str 类型会被经常使用,一些高频用法如下
字符串去空格
- 使用字符串的strip方法去除字符串开头的结尾的空格,也可以用字符串的replace方法替换掉所有的空格
1 | In [57]: ' I love python '.strip() |
字符串替换
- 使用字符串的replce进行字符替换
1 | # 替换所有的字符 |
字符串串联
- 使用字符串的join方法将一个容器型中的字符串联为一个字符串
1 | In [60]: '_'.join(['book', 'store','count']) |
查找子串位置
- 使用字符串的find方法返回匹配字符串的起始位置索引
1 | In [96]: 'i love python'.find('python') |
反转字符串
- 方法1,使用字符串的join方法和python内置函数将字符串反转
1 |
|
- 方法2,利用字符串的切片,只要列表可以使用的切片功能,字符串都可以用
1 | In [104]: s = "python" |
字符串切片
- 只要列表可以使用的切片功能,字符串都能用
1 | In [110]: s = '123456' |
分割字符串
根据指定字符或字符串,分割一个字符串时,使用方法 split。
join是字符串串联, 和可以把join和split 可看做一对互逆操作
1 | In [114]: 'I_love_python'.split('_') |
子串判断
判断 a 串是否为 b 串的子串。
- 方法1,使用成员运算符
in
1 | In [115]: a = 'abc' |
-
方法2,使用方法 find,返回字符串 b 中匹配子串 a 的最小索引
注意:str的find方法与list的index方法用途一样
1 | In [118]: b.find(a) |
去除重复元素
1 | In [257]: s = 'abcadcba' |
得到的结果是乱序的,如果要求和原来的循序一样,勿用此方法
正则表达式
字符串封装的方法,处理一般的字符串操作,还能应付。但是,稍微复杂点的字符串处理任务,需要靠正则表达式,简洁且强大。
首先,导入所需要的模块 re
1 | import re |
认识常用的元字符:
.匹配除 “\n” 和 “\r” 之外的任何单个字符。^匹配字符串开始位置$匹配字符串中结束的位置*前面的原子重复 0 次、1 次、多次?前面的原子重复 0 次或者 1 次+前面的原子重复 1 次或多次{n}前面的原子出现了 n 次{n,}前面的原子至少出现 n 次{n,m}前面的原子出现次数介于 n-m 之间( )分组,输出需要的部分
再认识常用的通用字符:
\s匹配空白字符\w匹配任意字母/数字/下划线\W和小写 w 相反,匹配任意字母/数字/下划线以外的字符\d匹配十进制数字\D匹配除了十进制数以外的值[0-9]匹配一个 0~9 之间的数字[a-z]匹配小写英文字母[A-Z]匹配大写英文字母
正则表达式,常会涉及到以上这些元字符或通用字符,下面是一些使用方式和小技巧
search 第一个匹配串
1 | import re |
match匹配开始位置
正则模块中,match、search 方法匹配字符串不同
- match 在原字符串的开始位置匹配
- search 在字符串的任意位置匹配
使用match方法的时候,如果子串不是在开始位置则报错
1 | import re |
把子串wor放在最前面,再使用match匹配就不会报错了
1 | s = 'world' |
match场景用的不多,如果只是匹配一个子串的位置,大多数情况下,使用search匹配
finditer匹配迭代器
使用正则模块,finditer 方法,返回所有子串匹配位置的迭代器
通过返回的对象 re.Match,使用它的方法 span 找出匹配位置
1 | In [119]: s = 'I am a good student' |
findall 所有匹配
findall 方法能查找出子串的所有匹配。
注意:
findall是返回所有的匹配finditer是返回所有匹配的位置
1 | s = '呼叫战狼,我是8371,请您在9.56秒后回到3号机场' |
目标查找出所有所有数字:通用字符 \d 匹配一位数字 [0-9],+ 表示匹配数字前面的一个字符 1 次或多次。
不带元字符+情况下,输出的是匹配到的一个个数字,这肯定不符合要求
1 | In [125]: s = '呼叫战狼,我是8371,请您在9.56秒后回到3号机场' |
带上元字符+
1 | In [125]: s = '呼叫战狼,我是8371,请您在9.56秒后回到3号机场' |
re.findall返回一个列表,里面包含四个数字,可以看到里面没有小数点,如果我们要找到9.56,应该怎么做呢?
匹配浮点数和整数
- 元字符
?表示前一个字符匹配 0 或 1 次 - 元字符
.?表示匹配小数点(.)0 次或 1 次。
匹配浮点数和整数,我们先来看正则表达式:r'\d+\.?\d+',该正则表达式可以理解为:先匹配1个或多个数字,再匹配小数点(.)0 次或 1 次,最后匹配1个或多个数字,分解演示如下:
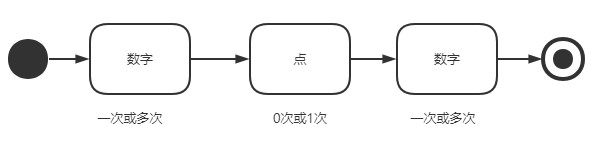
1 | s = '呼叫战狼,我是8371,请您在9.56秒后回到3号机场' |
可以看到,没有匹配到3,哪里出错了呢?
出现问题原因:r'\d+\.?\d+', 前面的\d+ 表示至少有一位数字,后面的\d+也表示至少有一位数字,因此,整个表达式至少会匹配两位数。
现在将最后的 + 后修改为 *,表示匹配前面字符 0 次、1 次或多次。如下所示:
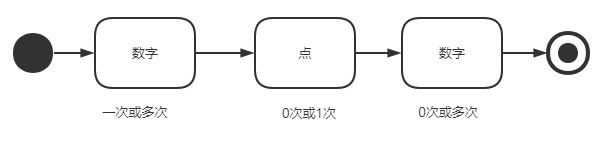
1 | In [132]: s = '呼叫战狼,我是8371,请您在9.56秒后回到3号机场' |
到这里就大功完成了,到这里我们再思考一下,如果把.?前面的\去掉以后会怎么样?如下:
1 | In [132]: s = '呼叫战狼,我是8371,请您在9.56秒后回到3号机场' |
可以看到,匹配到了一个汉字,为什么会出现这种情况呢?因为这里.?的含义就变了,之前是把\.?作为一个整体,现在.?的含义是附加到\d.?上。
\d+.?\d中.?含义如下:
.匹配除\n和\r之外的任何单个字符。- 那
.?就表示匹配\n和\r之外的任何单个字符0 次或 1 次。
我们看下演示图就知道了,\d+.?\d的演示图如下
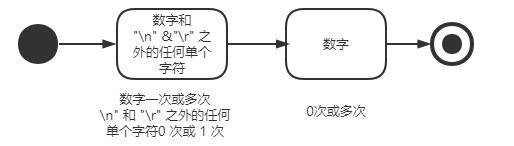
匹配正整数
案例:写出匹配所有正整数的正则表达式
我们先来看几个正则表达式即它们的含义
前面讲过
\d+表示数字出现1次或多次\d*表示数字出现0次或多次
\d*表示数字出现0次或多次,也就是会匹配所有的字符
1 | In [142]: s = [2,'我是1','1是我','123',0, 3,'已经9.56秒了',10,-1] |
^\d*$,在数字出现0次或多次前加上了开始位置,再后加上了结束位置。即必须是以数字的开头,以数字结尾,才能匹配到
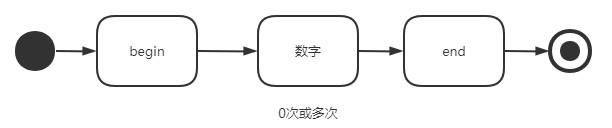
1 | In [142]: s = [2,'我是1','1是我','123',0, 3,'已经9.56秒了',10,-1] |
可以看到,匹配到了0,我们的目的是匹配所有正整数,所以不正确
^[1-9]*$表示匹配一个 0~9 之间的数字
1 | In [147]: s = [2,'我是1','1是我','123',0, 3,'已经9.56秒了',10,-1] |
可以看到,不能匹配10,因此这个也不正确
^[1-9]\d*$表示匹配一个 0~9 之间的数字并且匹配的数字出现0次或多次

1 | In [150]: s = [2,'我是1','1是我','123',0, 3,'已经9.56秒了',10,-1] |
re.I 忽略大小写
找出字符串中所有字符 t 或 T 的位置,不区分大小写。
1 | s = 'HELLO,World' |
1 | s = 'HELLO,World' |
re.split分割单词
正则模块中 split 函数强大,能够处理复杂的字符串分割任务
对于简单的分割,直接用分隔符
1 | In [153]: s = 'I-am-a-good-student' |
但是,对于分隔符复杂的字符串,split 函数就无能为力
如下字符串,可能的分隔符有, ; - . |和空格
1 | In [155]: s = 'I,,,am | ;a - good.. student' |
可以看到,直接使用是区分不开的,所有可以用正则模块中的split
\s 匹配空白字符
1 | In [157]: s = 'I,,,am | ;a - good.. student' |
注意:re.split默认匹配所有的候选字符,因此不需要元字符+了
但是,如果在字符串前面和后面加多个空格,\s就区分不开了,如下:
1 | In [163]: In [157]: s = ' I,,,am | ;a - good.. student ' |
这是,可以用字符串strip方法去除字符串的前后空格
1 | In [163]: In [157]: s = ' I,,,am | ;a - good.. student ' |
sub 替换匹配串
正则模块,sub 方法,替换匹配到的子串
1 | s = '你好,我是12306' |
compile 预编译
如果要用同一匹配模式,做很多次匹配,可以使用 compile 预先编译串
如果我们要:从一系列字符串中,挑选出所有正浮点数
正则表达式为:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$,字符 a|b表示 a 串匹配失败后,才执行 b 串
1 | s = [-1,10,0,7.21,0.5,'123','你好','3.25',11.0,9.] |