k-means算法是无监督的聚类算法,实现起来较为简单,k-means++可以理解为k-means的增强版,在初始化中心点的方式上比k-means更友好。
k-means的实现步骤如下:
从样本中随机选取k个点作为聚类中心点
对于任意一个样本点,求其到k个聚类中心的距离,然后,将样本点归类到距离最小的聚类中心,直到归类完所有的样本点(聚成k类)
对每个聚类求平均值,然后将k个均值分别作为各自聚类新的中心点
重复2、3步,直到中心点位置不在变化或者中心点的位置变化小于阈值
优点:
原理简单,实现起来比较容易
收敛速度较快,聚类效果较优
缺点:
初始中心点的选取具有随机性,可能会选取到不好的初始值。
k-means++是k-means的增强版,它初始选取的聚类中心点尽可能的分散开来,这样可以有效减少迭代次数,加快运算速度 ,实现步骤如下:
从样本中随机选取一个点作为聚类中心
计算每一个样本点到已选择的聚类中心的距离,用D(X)表示:D(X)越大,其被选取下一个聚类中心的概率就越大
利用轮盘法 的方式选出下一个聚类中心(D(X)越大,被选取聚类中心的概率就越大)
重复步骤2,直到选出k个聚类中心
选出k个聚类中心后,使用标准的k-means算法聚类
这里不得不说明一点,有的文献中把与已选择的聚类中心最大距离的点选作下一个中心点 ,这个说法是不太准确的,准的说是与已选择的聚类中心最大距离的点被选作下一个中心点的概率最大 ,但不一定就是改点,因为总是取最大也不太好(遇到特殊数据,比如有一个点离某个聚类所有点都很远)。
一般初始化部分,始终要给些随机。因为数据是随机的。
尽管计算初始点时花费了额外的时间,但是在迭代过程中,k-mean 本身能快速收敛,因此算法实际上降低了计算时间。
现在重点是利用轮盘法 的方式选出下一个聚类中心,我们以一个例子说明K-means++是如何选取初始聚类中心的。
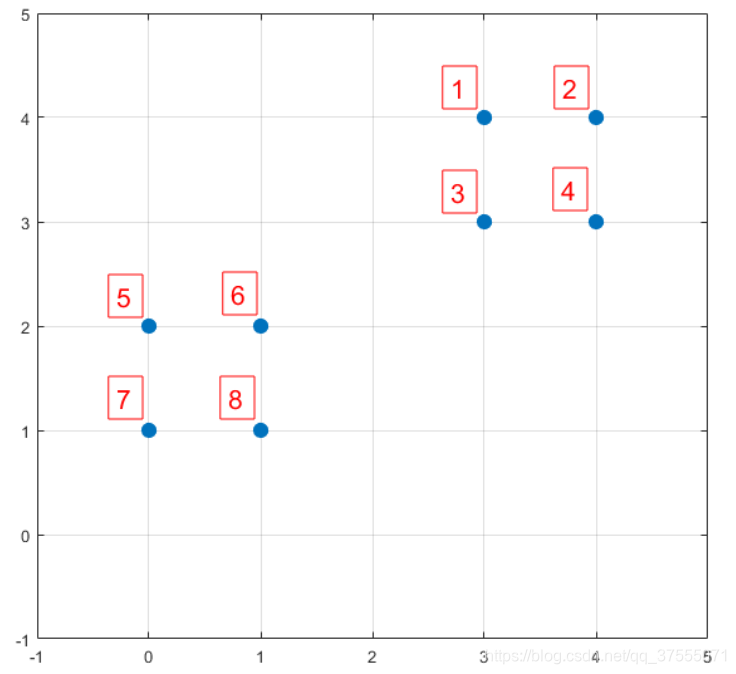
假如数据集中有8个样本,分布分布以及对应序号如下图所示:
D(X)是每个样本点与所选取的聚类中心的距离(即第一个聚类中心)
P(X)每个样本被选为下一个聚类中心的概率
Sum是概率P(x)的累加和,用于轮盘法选择出第二个聚类中心。
然后执行 k-means++的第三步:利用轮盘法 的方式选出下一个聚类中心,方法是随机产生出一个0~1之间的随机数,判断它属于哪个区间,那么该区间对应的序号就是被选择出来的第二个聚类中心了 。
在上图1号点区间为[0,0.2),2号点的区间为[0.2, 0.525),4号点的区间为[0.65,0.9)
从上表可以直观的看到,1号,2号,3号,4号总的概率之和为0.9,这4个点正好是离第一个初始聚类中心(即6号点)较远的四个点,因此选取的第二个聚类中心大概率会落在这4个点中的一个,其中2号点被选作为下一个聚类中心的概率最大。
这里选择的中心点是样本的特征(不是索引),这样做是为了方便计算,选择的聚类点(中心点周围的点)是样本的索引。
k-means实现
1 2 3 4 import numpy as npdef get_distance (x1, x2) : return np.sqrt(np.sum(np.square(x1-x2)))
1 2 3 4 5 6 7 8 9 10 11 12 import randomdef center_init (k, X) : n_samples, n_features = X.shape centers = np.zeros((k, n_features)) selected_centers_index = [] for i in range(k): sel_index = random.choice(list(set(range(n_samples))-set(selected_centers_index))) centers[i] = X[sel_index] selected_centers_index.append(sel_index) return centers
1 2 3 4 5 6 7 8 9 10 11 12 def closest_center (sample, centers) : closest_i = 0 closest_dist = float('inf' ) for i, c in enumerate(centers): distance = get_distance(sample, c) if distance < closest_dist: closest_i = i closest_dist = distance return closest_i
1 2 3 4 5 6 7 8 9 10 def create_clusters (centers, k, X) : clusters = [[] for _ in range(k)] for sample_i, sample in enumerate(X): center_i = closest_center(sample, centers) clusters[center_i].append(sample_i) return clusters
1 2 3 4 5 6 7 8 9 def calculate_new_centers (clusters, k, X) : n_samples, n_features = X.shape centers = np.zeros((k, n_features)) for i, cluster in enumerate(clusters): new_center = np.mean(X[cluster], axis=0 ) centers[i] = new_center return centers
1 2 3 4 5 6 7 8 def get_cluster_labels (clusters, X) : y_pred = np.zeros(np.shape(X)[0 ]) for cluster_i, cluster in enumerate(clusters): for sample_i in cluster: y_pred[sample_i] = cluster_i return y_pred
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def Mykmeans (X, k, max_iterations,init) : if init == 'kmeans' : centers = center_init(k, X) else : centers = get_kmeansplus_centers(k, X) for _ in range(max_iterations): clusters = create_clusters(centers, k, X) pre_centers = centers new_centers = calculate_new_centers(clusters, k, X) diff = new_centers - pre_centers if diff.sum() == 0 : break return get_cluster_labels(clusters, X)
1 2 3 4 5 6 7 X = np.array([[0 ,2 ],[0 ,0 ],[1 ,0 ],[5 ,0 ],[5 ,2 ]]) labels = Mykmeans(X, k = 2 , max_iterations = 10 ,init = 'kmeans' ) print("最后分类结果" ,labels)
1 2 3 4 5 6 from sklearn.cluster import KMeansX = np.array([[0 ,2 ],[0 ,0 ],[1 ,0 ],[5 ,0 ],[5 ,2 ]]) kmeans = KMeans(n_clusters=2 ,init = 'random' ).fit(X) print(kmeans.labels_)
k-means++实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def get_kmeansplus_centers (k, X) : n_samples, n_features = X.shape init_one_center_i = np.random.choice(range(n_samples)) centers = [] centers.append(X[init_one_center_i]) dists = [ 0 for _ in range(n_samples)] for _ in range(k-1 ): total = 0 for sample_i,sample in enumerate(X): closet_i = closest_center(sample,centers) d = get_distance(X[closet_i],sample) dists[sample_i] = d total += d total = total * np.random.random() for sample_i,d in enumerate(dists): total -= d if total > 0 : continue centers.append(X[sample_i]) break return centers
1 2 3 4 5 X = np.array([[0 ,2 ],[0 ,0 ],[1 ,0 ],[5 ,0 ],[5 ,2 ]]) labels = Mykmeans(X, k = 2 , max_iterations = 10 ,init = 'kmeans++' ) print("最后分类结果" ,labels)
1 2 3 4 X = np.array([[0 ,2 ],[0 ,0 ],[1 ,0 ],[5 ,0 ],[5 ,2 ]]) kmeans = KMeans(n_clusters=2 ,init='k-means++' ).fit(X) print(kmeans.labels_)
参考文档K-means与K-means++ K-means原理、优化及应用