Batch Normalization:批量归一化详解
为什么要使用BN
在深度学习中,层数很多,可能有几十层甚至上百层,每次训练激活的过程中,参数不断改变,导致后续每一层输入的分布也发生变化,而学习的过程就是要使每一层适应输入的分布,如果不做BN就会使模型学的很小心,也会使学习速率变慢,因此我们不得不降低学习率、小心地初始化。
那怎么才能让我们的模型学习的更高效呢?
原有的方式可能是歪着学的,学的效果不是很好,如下图B所示,现在我们需要让它激活到一个更适合学习的位置上,那就需要把它放到原点,这个位置更适合,这时候就需要BN了
原点周围更敏感,假定一开始你的数据不在原点周围,后面如果越来越偏,说不定会偏去哪,也就是指W一会大一会小,一会是正值,一会是负值,如下图B所示,也不利于更新。
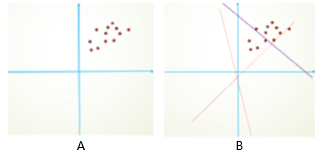
BN的工作原理
批量归一化 (Batch Normalization, BN)方法是一种有效的逐层归一化方法,可以对神经网络中任意的中间层进行归一化操作。
Batch Normalization,顾名思义,以进行学习时的batch为单位,按batch进行规范化。具体而言,把每层神经网络任意神经元输入值的分布强行拉回到均值为0方差为1的标准正态分布,用数学式表示的话,如下所示:
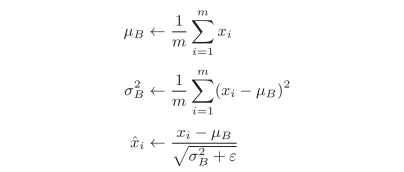
m代表batch的大小,为批处理数据的均值,为批处理数据的方差。
减去平均值是将数据放在原点周围,除以方差是因为让原来挤在一起的数据变得更均匀一些,如下图C->图D,原来分散的,也会让它们更加紧促一些,在这样一个数据分布里面,使得非线性变换函数的输入值落入对输入比较敏感的区域,从而避免梯度消失问题。这样输入的小变化就会导致损失函数较大的变化(使得梯度变大,避免梯度消失)。可以看出,提高参数更新的效率条件有:让数据的分布在原点附近,让数据分布不离散也不紧凑。
将数据转化为均值为0、方差为1的数据分布后,接着,BN层会对正规化后的数据进行缩放和平移的变换,用数学式可以如下表示:
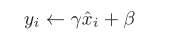
这里,γ和β是参数。一开始γ=1,β=0,然后再通过学习调整到合适的值。
思考:为什么BN要引入线性变化操作?
BN层相当于固定了每一层的输入分布,从而加速网络模型的收敛速到,但是这也限制了网络模型中数据的表达能力,浅层学到的参数信息会被BN的操作屏蔽掉,因此,BN层又增加了一个线性变换操作,让数据尽可能地恢复本身的表达能力
BN的优点
缓解梯度消失,加速网络收敛速度。BN层可以让激活函数(非线性变化函数)的输入数据
落入比较敏感的区域,缓解了梯度消失问题。
简化调参的负担,网络更稳定。在调参时,学习率调得过大容易出现震荡与不收敛,BN层则抑制了参数微小变化随网络加深而被放大的问题,因此对于参数变化的适应能力更强,更容易调参。
防止过拟合。BN层将每一个batch的均值与方差引入到网络中,由于每个batch的这两个值都不相同,可看做为训练过程增加了随机噪音,可以起到一定的正则效果,防止过拟合
在测试时应该注意的问题:
在测试时,由于是对单个样本进行测试,没有batch的均值与方差,通常做法是在训练时将每一个batch的均值与方差都保留下来,在测试时使用所有训练样本均值与方差的平均值。
PyTorch中使用BN层
1 | import torch.nn as nn |
BN的弊端
管BN层取得了巨大的成功,但仍有一定的弊端,主要体现在以下两点:
- 由于是在batch的维度进行归一化,BN层要求较大的batch才能有效地工作,而物体检测等任务由于占用内存较高,限制了batch的大小,这会限制BN层有效地发挥归一化功能。
- 数据的batch大小在训练与测试时往往不一样。在训练时一般采用滑动来计算平均值与方差(一个batch一个batch计算),在测试时直接拿训练集的平均值与方差来使用。这种方式会导致测试集依赖于训练集,然而有时训练集与测试集的数据分布并不一致。
因此,我们能不能避开batch来进行归一化呢?答案是可以的,最新的GN(Group Normalization)从通道方向计算均值与方差,使用更为灵活有效,避开了batch大小对归一化的影响。具体来讲,GN先将特征图的通道分为很多个组,对每一个组内的参数做归一化,而不是batch。GN之所以能够工作的原因,可以认为是在特征图中,不同的通道代表了不同的意义,例如形状、边缘和纹理等,这些不同的通道并不是完全独立地分布,而是可以放到一起进行归一化分析。
参考文档
深度学习之PyTorch物体检测实战[董洪义著]
深度学习入门基于Python的理论与实现[斋藤康毅著,陆宇杰译]
神经网络与深度学习[邱锡鹏著]