PyTorch之torchvision.transforms详解[原理+代码实现]
前言
我们知道,在计算机视觉中处理的数据集有很大一部分是图片类型的,如果获取的数据是格式或者大小不一的图片,则需要进行归一化和大小缩放等操作,这些是常用的数据预处理方法。如果参与模型训练中的图片数据非常有限,则需要通过对有限的图片数据进行各种变换,如缩小或者放大图片的大小、对图片进行水平或者垂直翻转等,这些都是数据增强的方法。庆幸的是,这些方法在torch.transforms中都能找到,在torch.transforms中有大量的数据变换类,有很大一部分可以用于实现数据预处理(Data Preprocessing)和数据增广(Data Argumentation)。
torchvision.transforms常用变换类
transforms.Compose
transforms.Compose类看作一种容器,它能够同时对多种数据变换进行组合。传入的参数是一个列表,列表中的元素就是对载入的数据进行的各种变换操作。
首先使用PIL加载原始图片
1 | #Pyton Image Library PIL 一个python图片库 |
输出:
(1102, 735)

1 | transformer = transforms.Compose([ |
输出:

transforms.Normalize(mean, std)
这里使用的是标准正态分布变换,这种方法需要使用原始数据的均值(Mean)和标准差(Standard Deviation)来进行数据的标准化,在经过标准化变换之后,数据全部符合均值为0、标准差为1的标准正态分布。计算公式如下:
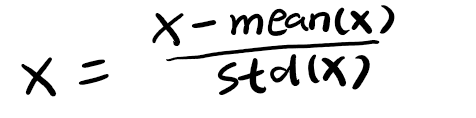
一般来说,mean和std是实现从原始数据计算出来的,对于计算机视觉,更常用的方法是从样本中抽样算出来的或者是事先从相似的样本预估一个标准差和均值。如下代码,对三通道的图片进行标准化:
1 | # 标准化是把图片3个通道中的数据整理到规范区间 x = (x - mean(x))/stddev(x) |
transforms.Resize(size)
对载入的图片数据按照我们的需要进行缩放,传递给这个类的size可以是一个整型数据,也可以是一个类似于 (h ,w) 的序列。如果输入是个(h,w)的序列,h代表高度,w代表宽度,h和w都是int,则直接将输入图像resize到这个(h,w)尺寸,相当于force。如果使用的是一个整型数据,则将图像的短边resize到这个int数,长边则根据对应比例调整,图像的长宽比不变。
1 | # 等比缩放 |
输出:
(335, 224)

transforms.Scale(size)
对载入的图片数据我们的需要进行缩放,用法和torchvision.transforms.Resize类似。。传入的size只能是一个整型数据,size是指缩放后图片最小边的边长。举个例子,如果原图的height>width,那么改变大小后的图片大小是(size*height/width, size)。
1 | # 等比缩放 |
输出:
(335, 224)

transforms.CenterCrop(size)
以输入图的中心点为中心点为参考点,按我们需要的大小进行裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h,w)的序列。如果输入的是一个整型数据,那么裁剪的长和宽都是这个数值
1 | test3 = transforms.CenterCrop((500,500))(img) |
输出:
(500, 500)

1 | test4 = transforms.CenterCrop(224)(img) |
输出:
(224, 224)

transforms.RandomCrop(size)
用于对载入的图片按我们需要的大小进行随机裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h,w)的序列。如果输入的是一个整型数据,那么裁剪的长和宽都是这个数值
1 | test5 = transforms.RandomCrop(224)(img) |
输出:
(224, 224)

1 | test6 = transforms.RandomCrop((300,300))(img) |
输出:
(300, 300)

transforms.RandomResizedCrop(size,scale)
先将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为size的大小。即先随机采集,然后对裁剪得到的图像安装要求缩放,默认scale=(0.08, 1.0)。scale是一个面积采样的范围,假如是一个100*100的图片,scale = (0.5,1.0),采样面积最小是0.5*100*100=5000,最大面积就是原图大小100*100=10000。先按照scale将给定图像裁剪,然后再按照给定的输出大小进行缩放。
1 | test9 = transforms.RandomResizedCrop(224)(img) |
输出:
(224, 224)

1 | test9 = transforms.RandomResizedCrop(224,scale=(0.5,0.8))(img) |
输出:
(224, 224)

transforms.RandomHorizontalFlip
用于对载入的图片按随机概率进行水平翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值0.5。
1 | test7 = transforms.RandomHorizontalFlip()(img) |
输出:
(1102, 735)

transforms.RandomVerticalFlip
用于对载入的图片按随机概率进行垂直翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值0.5。
1 | test8 = transforms.RandomVerticalFlip()(img) |
输出:
(1102, 735)

transforms.RandomRotation
1 | transforms.RandomRotation( |
- 功能:按照degree随机旋转一定角度
- degree:加入degree是10,就是表示在(-10,10)之间随机旋转,如果是(30,60),就是30度到60度随机旋转
- resample是重采样的方法
- center表示中心旋转还是左上角旋转
1 | test10 = transforms.RandomRotation((30,60))(img) |

transforms.ToTensor
用于对载入的图片数据进行类型转换,将之前构成PIL图片的数据转换成Tensor数据类型的变量,让PyTorch能够对其进行计算和处理。
transforms.ToPILImage
用于将Tensor变量的数据转换成PIL图片数据,主要是为了方便图片内容的显示。
torchvision.transforms编程实战
1 | # RandomResizedCrop 将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为制定的大小 |
输出:
原图大小: (1102, 735)
随机裁剪后的大小: (224, 224)

1 | # 以输入图的中心点为中心点做指定size的crop操作 |
输出:

1 | # 以给定的概率随机水平旋转给定的PIL的图像,默认为0.5 |
输出:

源码在PyTorch之torchvision.transforms实战,请自提!
参考文档
深度学习pytoch实战计算机视觉(唐进民著)