深入理解GAN对抗生成网络
什么是GAN
Generative Adversarial Networks,生成式对抗网络,Ian Goodfellow 在2014 年提出的一种生成式模型
基本思想来自博弈论的二人零和博弈(纳什均衡), 由一个生成器和一个判别器构成,通过对抗学习来训练
- 生成器的目的是尽量去学习真实的数据分布
- 判别器的目的是尽量正确判别输入数据是来自真实数据还是来自生成器
- 生成器和判别器就是一个矛和盾互相PK的过程
- 为了取得游戏胜利,这两个游戏参与者需要不断优化, 各自提高自己的生成能力和判别能力,这个学习优化过程就是寻找二者之间的一个纳什均衡

G代表生成器,D代表判别器,Z是输入源,称为Noise source,就是一个随机编码。给出一个random code(即Z)由生成器G生成假数据X’,假数据X’和真实数据X喂给判别器D,由D判别出哪个是real,哪个是fake,这个就是gan的基本原理

纳什均衡
我们以囚徒困境的例子来解释纳什均衡的含义
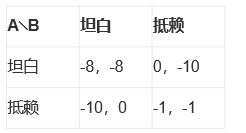
A和B属于零和游戏,需要在A和B的决策中进行Trade Off(权衡),由此看出,抵赖对两个人来说都是最优的结果,这个就是纳什均衡。
亚当·斯密的“看不见的手”,在市场经济中,每一个人都从利己的目的出发,不断调和与迭代,最终全社会达到利他的效果
GAN的学习过程
GAN的学习过程其实就是把D和G达成一个均衡,这是我们的目标,因此不仅要训练G,也要训练D
为什么D和G是对抗的?
G是生成器,它生成的数据是虚假的,它目标是让生成的数据骗过D。D是判别器,它的目标是要把虚假的数据给找出来,因此D和G是对抗的
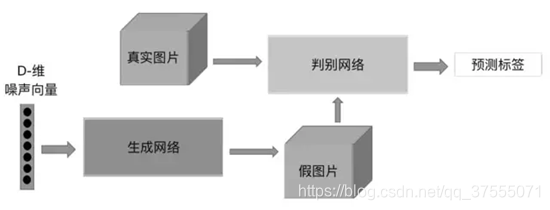
对于 GAN 的学习过程 ,需要训练模型D来最大化判别数据来源于真实数据或者伪数据分布 ,同时,我们需要训练模型 G来最小化 loss。
我们该采用怎样的优化方法,对生成器G和判别器D进行优化呢?
- Step1,固定生成器 G=>优化判别器 D,让D的判别准确率最大化
- Step2,固定判别器 D => 优化生成器 G,让D的判别准确率最小化
训练 GAN 时,在同一轮参数更新中,通常对 D 的参数更新 k 次,再对 G的参数更新 1 次,这样做的目的是让D学的更快点,因为我们最终要的是G,为此需要把D这个教练先变得越来越好,由此才能训练出更好的G
Generator与Discriminator的工作原理
- Generator,在输入一个随机编码(random code)z之后,它将输出一幅由神经网络自动生成的、假的图片G(z)
- Discriminator,接受G输出的图像作为输入,然后判断这幅图像的真假,真的输出1,假的输出0
- G生成的图像会越来越逼真,D也越来越会判断图片的真假,最后我们就不要D了,直接用G来生成图像
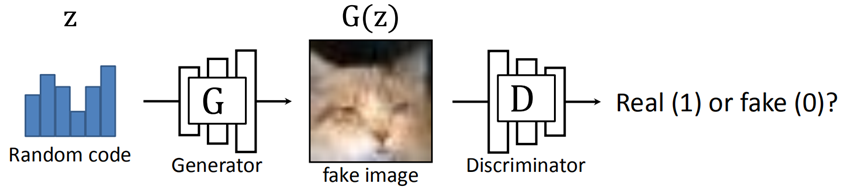
我们就是要在最大化D的能力的前提下,最小化D对G的判断能力 ,所以称之为 最小最大值问题
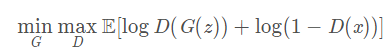
损失函实际上是一个交叉熵,判别器的目的是尽可能的令D(x)接近1(对于真图像x的处理评分要高),令D(G(z))接近0(对于假图像G(z)的处理评分要尽量降低),所以D主要是最大化上面的损失函数(让D的辨别能力更强),G恰恰相反,他主要是最小化上述损失函数(让生成的假图像G(z)变得更真实)。
为了增强D的能力,我们分别考虑输入真的图像和假的图像的情况
D的目标是什么?G的目标是什么?
- D的目标是:D(G(z))处理的是假图像G(z) => 评分D(G(z))要尽量降低,对于真图像x的处理 => 评分要高,这样D的辨别能力才会更强
- G的目标是:让生成的假图像G(z)变得更真实、更逼真,让D难以辨别
GAN的局限性
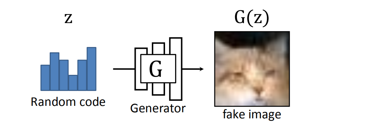
用户输入random code由生成器G参数 fake image即G(Z),传统的GAN中会出现如下局限性:
- 在传统的GAN里,由于没有用户控制能力,输入一个随机噪声,就会输出一幅随机图像(可能输出猫在左边或是猫在右边的图像)
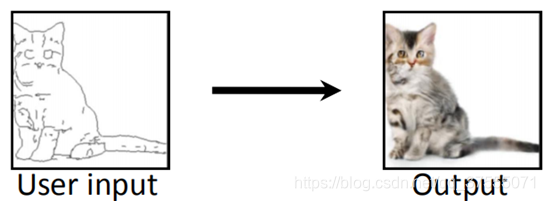
这里user input 是指输入的random code,output是G生成的G(Z),还要从现实世界中取一张或者画一张真实图像,与output一起输入判别器
- 低分辨率(Low resolution)和低质量(Low quality)问题
生成的图片看起来不错,但放大看,会发现细节相当模糊


如何改善GAN的局限性
如改善GAN的局限性可以从以下两个方面入手:
- 提高GAN的用户控制能力
- 提高GAN生成图片的分辨率和质量
从以上两个方面提出新的算法模型:
-
pix2pix,有条件的使用用户输入,使用成对的数据(paired data)进行训练。比如,输入的是猫在左边,你就不能生成猫在右边的图。Pix2pix的缺点:在训练过程中,需要人为给它标出数据的对应关系,比如 现在的输入条件是猫在左边,人要给它画一张或找一张猫在左边的图像,才会让G更好的学习,以产生猫在右边的图像,这对数据源的要求会很高
-
CycleGAN,使用不成对的数据(unpaired data)就能训练。
以马为例,马训练马是成对的数据,用马生成斑马,是不成对数据。由于现实生活中成对的样本比较少,对于没有成对样本的情况,使用CycleGAN,CycleGAN有两个生成器,马->斑马,斑马->马,我们最终想要的是马->斑马,利用理论上开始的马和马->斑马->马是一样的,同时优化马->斑马,斑马->马两个生成器,最终使用马->斑马。
CycleGAN本质是优化生成器的一个思想,拿文本翻译来说,你把一段英文翻译成中文,再把中文翻译回英文,假如翻译回来的英文和一开始的英文天差地别,那么这个两次翻译的结果肯定是很差的;反之,如果能够让翻译回来的英文和原本的一样,就相当于是改进了两次翻译的效果,CycleGAN利用这种方式来优化生成器。 -
pix2pixHD,生成高分辨率、高质量的图像

未来还会持续更新:
- Conditional GAN
- pix2pix
- CycleGAN
- GauGAN
谢谢支持!