使用VGG迁移学习开启《猫狗大战挑战赛》,内容如下:
猫狗大战挑战由Kaggle于2013年举办的,目前比赛已经结束,不过仍然可以把AI研习社猫狗大战赛平台 1= dog,0 = cat 。这里使用在 ImageNet 上预训练的 VGG 网络模型进行测试,因为原网络的分类结果是1000类,所以要进行迁移学习,对原网络进行 fine-tune (即固定前面若干层,作为特征提取器,只重新训练最后两层),并把测试结果提交到该平台。那么,现在就让我们开始吧。
前期如何把解压后的竞赛数据集 放到colab上着实耗费了我大量的时间,我认为非常有必要把这个单独作为一章讲一下。如果你本地有很强的GPU,不需要在colab上跑代码,这章节可以忽略,由于我的电脑跑不动这么多数据,GPU也不行,所以只能在colab上运行。在这个过程中许多问题本是可以避免的,由于对一些操作和指令不熟练,导致许多时间白白流失,即打消了初学者的自信心,也拖慢了实验的进度,究其原因,主要有以下几点:
在google drive上传和解压数据集时间特别慢,需要数十个小时
colab运行时间有时限,长时间不操作(大概20分钟左右)会导致当前训练的数据被回收
猫狗大战数据集是没有标签的,需要自己定义Dataset类加载数据
现在就来一个个解决上面的几个痛点吧!
(1)colab上传和解压大数据集
我们的目的是要在colab上读取竞赛数据集的图片,达到目的的方式有三个:
方式一:把数据集压缩包上传到google drive,在drive上解压
方式二:数据集解压后再上传到google drive
方式三:把数据集压缩包上传到google drive,在colab连接的虚拟机上解压
上面几种方式哪个好呢?我先不直接说结果,来实验下吧!
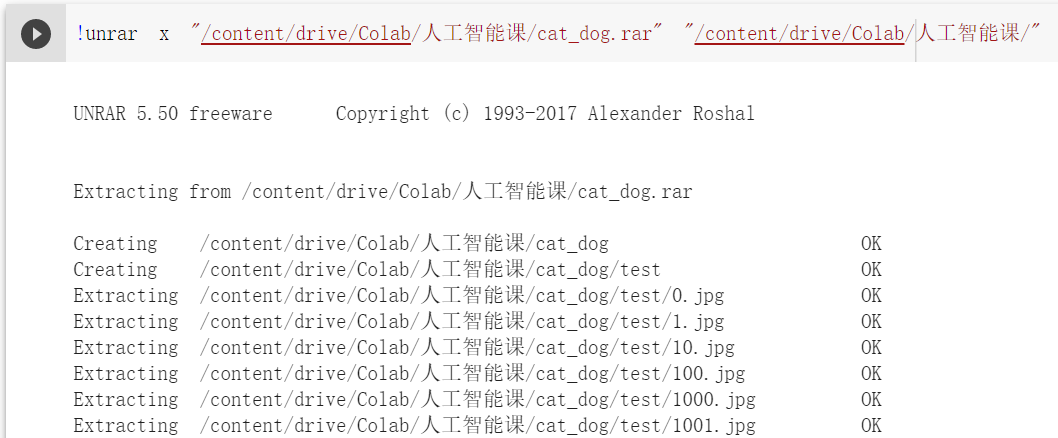
首先,采用方式一,把数据集压缩包上传到google drive,在drive上解压,操作很简单,在google drive上右键上传竞赛数据集cat_dog.rar 时间竟然要十几个小时 ,具体操作如下:
我大致算了一下,每张图片解压时间5秒钟左右,24000张图片要大约33小时啊!!!所以,这种方式直接pass掉。
再来看,方式二,把数据集解压后再上传到google drive,解压后的数据集文件夹大小虽然只有五百多兆,但上传速度特别慢,大概要5至7个小时,并且一旦中间断网或是网络不稳定,极有可能导致数据损坏 。我就是花费了大半天时间把所有解压后的文件上传完了,由于中间网络不稳定,导致数据读取不正确,最终这种方式也放弃了,哎,说多了都是泪!
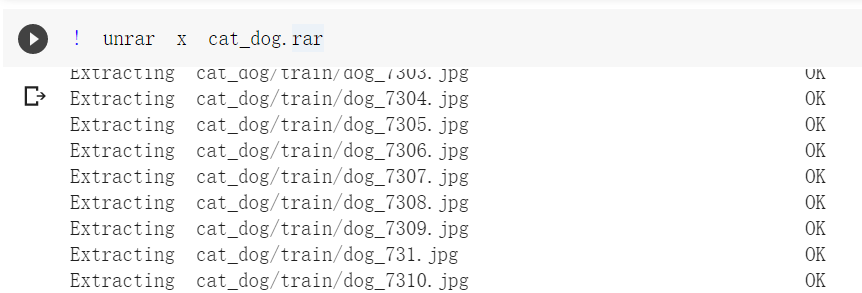
最后,就只有方式三了,把数据集压缩包上传到google drive,在colab连接的虚拟机上解压文件,方法是:
将google drive上数据集文件cat_dog.rar拷贝到colab连接的虚拟机上1 !cp -i /content/drive/Colab/人工智能课/cat_dog.rar /content/
在虚拟机上解压压缩文件:1 2 ! apt-get install rar ! unrar x cat_dog.rar
这种方式速度非常快,如果操作正确,解压时间仅有一分钟左右 ,非常值得推荐!
(2)阻止Colab自动掉线
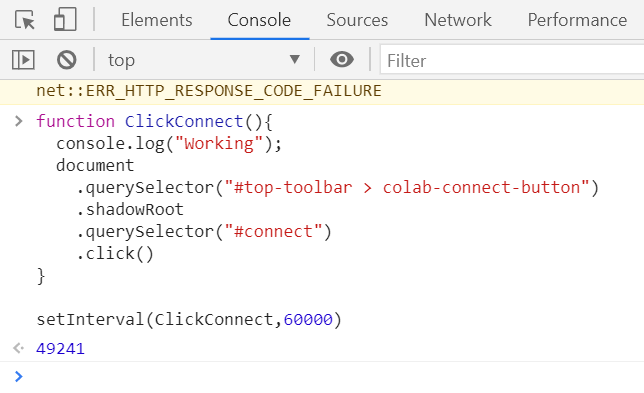
在colab上训练代码,页面隔一段时间无操作之后就会自动掉线,之前训练的数据都会丢失。现在你体会到我之前连续几个小时在google drive解压数据集文件的艰辛路程了吧。不过好在最后终于找到了一种可以让其自动保持不离线的方法,用一个js程序自动点击连接按钮。代码如下:
1 2 3 4 5 6 7 8 9 10 function ClickConnect ( console .log("Working" ); document .querySelector("#top-toolbar > colab-connect-button" ) .shadowRoot .querySelector("#connect" ) .click() } setInterval(ClickConnect,60000 )
使用方式是:按快捷键ctrl+shift+i,并选择Console,然后复制粘贴上面的代码,并点击回车,该程序便可以运行了,如下所示:
(3)猫狗大战数据集是没有标签的,需要自己定义Dataset类才能加载数据
猫狗大战数据集是没有标签的,但是从其训练集和验证集的图片名字可以获取标签,这就需要我们自己定义Dataset类了,由于这个部分篇幅较多,我们放在下一章讲吧。
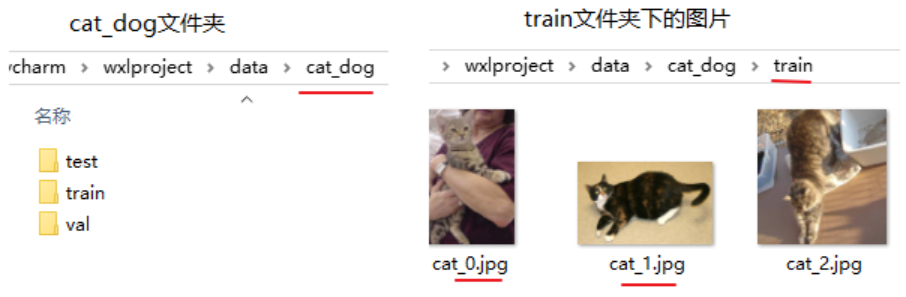
传统的mnist数据集是集成到torchvision.datasets,我们使用datasets.MNIST就可以方便加载数据,不用做过多的其它处理,而猫狗大战竞赛数据集是如下图方式,并没有用标签对文件夹分类存放,所以我们需要通过图片名称获取标签,并自定义Dataset类加载图片。
我定义的Dataset类如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from torch.utils.data import Dataset,DataLoaderclass MyDataset (Dataset) : def __init__ (self, txt, data_path=None, transform=None, target_transform=None, loader=default_loader) : super(MyDataset, self).__init__() file_path = data_path + txt file = open(file_path, 'r' , encoding='utf8' ) imgs = [] for line in file: line = line.split() imgs.append((line[0 ],line[1 ].rstrip('\n' ))) self.imgs = imgs self.transform = transform self.target_transform = target_transform self.loader = loader self.data_path = data_path def __getitem__ (self, index) : imgName, label = self.imgs[index] imgPath = imgName img = self.loader(imgPath) if self.transform is not None : img = self.transform(img) label = torch.from_numpy(np.array(int(label))) return img, label def __len__ (self) : return len(self.imgs) def default_loader (path) : return Image.open(path).convert('RGB' )
具体要加载图片数据还要进行几个处理,即事先准备好train、val数据集的路径和标签,以及test数据集的路径,然后使用MyDataset加载图片路径文件,最后就可以通过torch.utils.data.DataLoader加载图片数据了。具体步骤如下:
(1)首先,读取cat_dog文件夹下的图片路径
1 2 3 4 5 6 7 def read_file_name (file_dir) : filename = [] for root, dirs, files in os.walk(file_dir): filename = files break return filename
(2)然后将文件名格式化为竞赛要求的类型,这里cat标签为0,dog为1
1 2 3 4 5 6 7 8 9 10 def format_inputAndlabel (file_dir) : format_result = [] filename = read_file_name(file_dir) for n in filename: if "cat" in n: format_result.append(n+" 0" ) else : format_result.append(n+" 1" ) return format_result
(3)分别传入train、test、val路径读取数据
1 2 3 4 format_train_result = format_inputAndlabel("cat_dog/train" ) format_test_result = format_inputAndlabel("cat_dog/test" ) format_val_result = format_inputAndlabel("cat_dog/val" )
(4)由于自定义的DataSet必须知道文件路径,所以先将格式化的文件名写入文件里,再用自定义的MyDataset读取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def convert_format (content) : result = [] for t in content: v = t.split('.' ) result.append(int(v[0 ])) return result def write_file (path,file_prefix,content) : with open(path, 'w' , encoding='utf8' ) as f: for line in content: f.write(file_prefix+line+'\n' ) def write_test_file (path,test_file_prefix,content) : content=convert_format(content) content.sort() with open(path, 'w' , encoding='utf8' ) as f: for line in content: f.write(test_file_prefix+str(line)+'.jpg 0' +'\n' ) write_file(path="cat_dog/train.txt" ,file_prefix="cat_dog/train/" ,content=format_train_result) write_file(path="cat_dog/val.txt" ,file_prefix="cat_dog/val/" ,content=format_val_result) write_test_file(path="cat_dog/test.txt" ,test_file_prefix="cat_dog/test/" ,content=format_test_result)
(5)对数据进行预处理变换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from torch.utils.data import Dataset,DataLoaderimport torchvision.transforms as transformsnormalize = transforms.Normalize(mean=[0.485 , 0.456 , 0.406 ], std=[0.229 , 0.224 , 0.225 ]) train_transformer = transforms.Compose([ transforms.Resize(256 ), transforms.transforms.RandomResizedCrop((224 ), scale = (0.5 ,1.0 )), transforms.RandomHorizontalFlip(), transforms.ToTensor(), normalize]) val_transformer = transforms.Compose([ transforms.Resize(224 ), transforms.CenterCrop(224 ), transforms.ToTensor(), normalize ])
(6)使用MyDataset加载图片路径文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cmd_path='cat_dog/' trainset = MyDataset(txt='train.txt' ,data_path=cmd_path,transform=train_transformer) valset = MyDataset(txt='val.txt' ,data_path=cmd_path,transform=val_transformer) testset = MyDataset(txt='test.txt' ,data_path=cmd_path,transform=val_transformer) print('训练集:' ,trainset.__len__()) print('验证集:' ,valset.__len__()) print('测试集:' ,testset.__len__()) """ 输出: 训练集: 20000 验证集: 2000 测试集: 2000 """
(7)使用torch.utils.data.DataLoader加载图片数据,并将其放入dataloaders_dict
1 2 3 4 5 6 7 batchsize=128 train_loader = DataLoader(trainset, batch_size = batchsize, drop_last = False , shuffle = True ) val_loader = DataLoader(valset, batch_size = batchsize, drop_last = False , shuffle = False ) test_loader = DataLoader(testset, batch_size = batchsize, drop_last = False , shuffle = False ) dataloaders_dict = {'train' :train_loader,'val' :val_loader,'test' :test_loader}
最终,数据集文件被放入dataloaders_dict,后面就可以通过该字典方便的传入相应的数据集了。
VGG 模型如下图所示,主体由三种元素组成:
卷积层(CONV)是发现图像中局部的 pattern
全连接层(FC)是在全局上建立特征的关联
池化(Pool)是给图像降维以提高特征的 invariance(不变性)
关于VGG模型的更详细介绍,可以参考我的博客深入解读VGG网络结构
默认情况下,当我们加载预训练的模型时,所有参数都具有requires_grad = True,如果我们从头开始或进行微调训练就不用更改。但是,如果我们要进行特征提取,并且只想为新初始化的图层计算梯度,那么我们希望所有其他参数都不需要梯度更新,需要用set_parameter_requires_grad函数将模型中参数的requires_grad属性设置为False,具体如下:
1 2 3 4 def set_parameter_requires_grad (model, feature_extracting) : if feature_extracting: for param in model.parameters(): param.requires_grad = False
这里我使用预训练好的VGG模型进行迁移学习,只想更新最后一层的参数,并且希望所有其他参数都不需要梯度更新,所以要用set_parameter_requires_grad函数将模型最后一层参数的requires_grad属性设置为False,由于猫狗大战数据集是二分类,需要把最后的nn.Linear 层由1000类,替换为2类。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 def initialize_model (num_classes, feature_extract, use_pretrained=True) : model_vgg = None model_vgg = models.vgg16(pretrained=use_pretrained) set_parameter_requires_grad(model_vgg, feature_extract) model_vgg.classifier[6 ] = nn.Linear(4096 , num_classes) model_vgg.classifier.add_module('7' ,torch.nn.LogSoftmax(dim = 1 )) return model_vgg model_vgg_new = initialize_model(num_classes=2 ,feature_extract = True ,use_pretrained=True ) print(model_vgg_new.classifier)
输出model_vgg_new的classifier层,如下所示,可以看到最后一层全连接输出为2,并且使用LogSoftmax为output层。
1 2 3 4 5 6 7 8 9 10 Sequential( (0): Linear(in_features=25088, out_features=4096, bias=True) (1): ReLU(inplace=True) (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU(inplace=True) (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=4096, out_features=2, bias=True) (7): LogSoftmax(dim=1) )
训练定义好的VGG模型,即训练最后一层全连接层,具体操作步骤如下:
(1)创建损失函数和优化器
损失函数 NLLLoss() 的输入是一个对数概率向量和一个目标标签,它不会为我们计算对数概率,适合最后一层是log_softmax()的网络。Adam优化器是目前性能比较好的优化器之一,因此这里采用Adam。
1 2 3 4 5 6 7 8 9 ''' 第一步:创建损失函数和优化器 ''' criterion = nn.NLLLoss() lr = 0.001 optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6 ].parameters(),lr = lr)
(2)判断是否存在GPU设备,并将model切换到相应的device
1 2 3 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" ) print('Using gpu: %s ' % torch.cuda.is_available()) model_vgg_new.to(device)
(3)训练模型
这里我定义了一个train_model训练的方法,并将验证集上结果最好的一次训练存储下来,为了减少训练时间,我把epoch设置为4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 ''' 第三步:训练模型 ''' def train_model (model, dataloaders, criterion, optimizer, num_epochs=25 ) : since = time.time() val_acc_history = [] best_model_wts = copy.deepcopy(model.state_dict()) best_acc = 0.0 for epoch in range(num_epochs): print('Epoch {}/{}' .format(epoch, num_epochs - 1 )) print('-' * 10 ) for phase in ['train' , 'val' ]: if phase == 'train' : model.train() else : model.eval() running_loss = 0.0 running_corrects = 0 for inputs, labels in dataloaders[phase]: inputs = inputs.to(device) labels = labels.to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels.long()) _, preds = torch.max(outputs, 1 ) if phase == 'train' : loss.backward() optimizer.step() running_loss += loss.item() * inputs.size(0 ) running_corrects += torch.sum(preds == labels.data) epoch_loss = running_loss / len(dataloaders[phase].dataset) epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset) print('{} Loss: {:.4f} Acc: {:.4f}' .format(phase, epoch_loss, epoch_acc)) if phase == 'val' and epoch_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict()) if phase == 'val' : val_acc_history.append(epoch_acc) print() time_elapsed = time.time() - since print('Training complete in {:.0f}m {:.0f}s' .format(time_elapsed // 60 , time_elapsed % 60 )) print('Best val Acc: {:4f}' .format(best_acc)) model.load_state_dict(best_model_wts) return model, val_acc_history model_new_vgg, hist = train_model(model_vgg_new, dataloaders_dict, criterion, optimizer_vgg, num_epochs=4 )
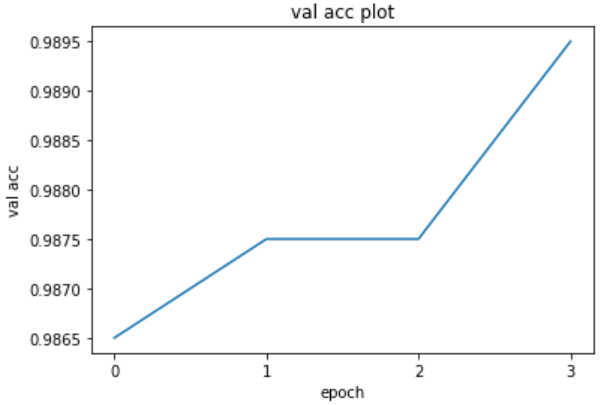
经过4次epoch,输出的记录如下,可以看到虽然训练次数不多,但是在验证集上效果还是很不错的
1 2 3 4 5 6 7 8 9 import matplotlib.pyplot as plt%matplotlib inline import numpy as npplt.title(u"val acc plot" ) plt.xlabel(u"epoch" ) plt.ylabel(u"val acc" ) acc= hist plt.xticks(range(len(acc))) plt.plot(acc)
(1)保存训练好的模型
pytorch保存和加载模型有两种方式,不同的保存方式对应不同的读取方式 ,两者各有利弊。
方式一:直接保存整个模型
1 2 torch.save(model_new_vgg, 'model_new_vgg.pt' ) model_new_vgg = torch.load('model_new_vgg.pt' )
方式二:只保存模型中的参数
1 2 3 model = initialize_model(num_classes=2 ,feature_extract = True ,use_pretrained=True ) model.to(device) model.load_state_dict(torch.load("model_new_vgg.pt" ))
可以看到,用第一种方法能够直接保存模型,加载模型的时候直接把读取的模型给一个参数就行。而第二种方法则只是保存参数,在读取模型参数前要先定义一个模型 (模型必须与原模型相同的构造),然后对这个模型导入参数。虽然麻烦,但是可以同时保存多个模型 的参数,而第一种方法则不能,而且第一种方法有时不能保证模型的相同性 (你读取的模型并不是你想要的)。所以,这里我采用第二种方式来保存并加载模型。
(2)对模型进行测试
接下来就要用test数据集对模型进行测试了,把测试结果保存到pred_outputs,具体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def test_model (model, test_loader) : model.eval() total,correct = 0 ,0 pos = 0 pred_outputs= np.empty(len(test_loader.dataset),dtype=np.int) with torch.no_grad(): for inputs, labels in test_loader: inputs = inputs.to(device) outputs = model(inputs) _, preds = torch.max(outputs, 1 ) pred_outputs[pos:pos+len(preds)]=preds.cpu().numpy() pos += len(preds) return pred_outputs pred_outputs = test_model(model,dataloaders_dict['test' ])
(3)将测试结果写入cat_dog_result.csv
1 2 3 with open("cat_dog_result.csv" , 'w' ) as f: for i in range(len(test_loader.dataset)): f.write("{},{}\n" .format(i, pred_outputs[i]))
因为我是在colab环境上训练的,还要把cat_dog_result.csv拷贝到google drive才能下载,命令如下:
1 !cp -i /content/cat_dog_result.csv /content/drive/
(4)提交测试结果
把cat_dog_result.csv提交到AI研习社猫狗大战–经典图像分类题
可以看到,只训练了4次epoch,测试就达到了98.9的准确率,把epoch设置得更大,结果应该会更好,由于时间原因,就不训练了。
从加载猫狗大战竞赛数据集到colab上,到测试完模型并提交,我大概花费了几天的时间,并且主要时间不是用在定义模型和调参上,而是如何处理数据上。我认为这次的收获还是很大的,因为我知道了如何以最快最有效的方式在colab上加载要训练的数据 ,并定义了自己Dataset类,以后对于任何类型、任何格式的训练数据,我应该都能定义相应Dataset类并且去处理它 。这次我用了近三天,下次可能一个小时不到就搞定了,这难道不是一个巨大的进步吗?此外,我通过预训练好的VGG模型进行迁移学习,训练了猫狗大战数据集,仅训练了4次epoch,测试数据就达到了98.9的准确率,说明预训练好的VGG模型是非常容易学习的,以后再遇到类似的识别分类任务,就不需要从头开始训练了,真的是非常快速又方便。
最后,附上我的colab共享地址:https://drive.google.com/file/d/1t-DVQwo92dBuy3JgNhdYFD_CndwyBE3U/view?usp=sharing
里面格式有点乱,但是内容一点都不少哦!