1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| def train_model(image_data,image_label,weights,bias,lr):
loss_value_before=1000000000000000.
loss_value=10000000000000.
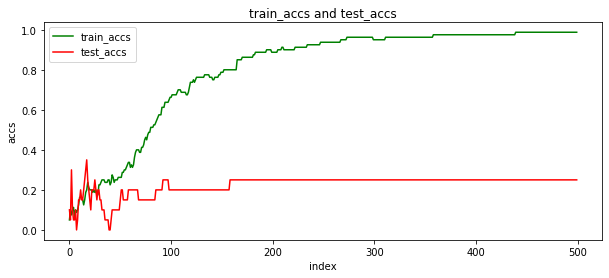
train_accs = []
test_accs = []
for epoch in range(0,500):
loss_value_before=loss_value
loss_value=0
for i in range(0,80):
y = model(image_data[i],weights,bias)
gt = image_label[i]
loss = torch.sum((y[0,gt:gt+1]-gt).mul(y[0,gt:gt+1]-gt))
loss_value += loss.data.item()
loss.backward()
weights.data.sub_(weights.grad.data*lr)
weights.grad.data.zero_()
bias.data.sub_(bias.grad.data*lr)
bias.grad.data.zero_()
train_acc = get_acc(image_data,image_label,weights,bias,0,80)
test_acc = get_acc(image_data,image_label,weights,bias,80,100)
train_accs.append(train_acc)
test_accs.append(test_acc)
show_acc(train_accs,test_accs)
|